پایگاه داده چیست و چه کاربردی دارد؟
?What is Database

در طول زندگی همواره با اطلاعات مختلفی رو به رو می شویم و گاهی تصمیم می گیریم که آن اطلاعات را جایی ذخیره کنیم تا بتوانیم به صورت بلندمدت به آن ها دسترسی داشته باشیم و برایمان محفوظ باشند. قبل از اینکه توضیحات کاملی در مورد اینکه پایگاه داده ارائه کنیم و بصورت تخصصی به پاسخ این سوال بپردازیم که «پایگاه داده چیست و چه کاربردی دارد؟» بهتر است با یک مثال ساده از زندگی واقعی خودمان شروع کنیم:
پایگاه داده در زندگی واقعی

از روزی که «گراهام بلِ» یونانی دستگاهی به نام تلفن را اختراع کرد تا به امروز، بخشی از زندگی ما به این اختراع رویایی و جذاب گره خورده است! ما می دانیم که هر تلفن یک شماره به خصوص دارد و برای ارتباط با آن نیاز است که با شماره آن تلفن تماس حاصل شود.
امروزه نیاز داریم تا با افراد زیادی به وسیله تلفن ارتباط بگیریم و طبیعتا این افراد هرکدام شماره تلفن مخصوصی نیز دارند. اما ما در نهایت می توانیم چند شماره تلفن را به خاطر بسپاریم؟ 5 شماره؟ 10 شماره؟ یا نهایتا 50 شماره؟!
در عصر ارتباطات ممکن است نیاز داشته باشیم تا با صدها نفر ارتباط تلفنی داشته باشیم ولی چطور باید شماره تمام این افراد را در اختیار داشته باشیم؟
همانطور که می دانید هر تلفن هوشمند، یک برنامه پیشفرض با نام مخاطبین و هر تلفن خانگی یک دفترچه تلفن دارد که در آن تمام شماره هایی را که نیاز داریم، ذخیره می کنیم. این اطلاعات حتی فراتر از شماره تلفن افراد است و می توانیم برای هر شخص در دفترچه خود، نام، پست الکترونیک، آدرس و مقادیر مختلف دیگری را در نظر بگیریم و یادداشت کنیم.
پایگاه داده یا دیتابیس دقیقا همین فرآیند را انجام می دهد، با این تفاوت که نوشتن و بازخوانی اطلاعات در آن به صورت اتوماتیک و سیستمی انجام می پذیرد.
در ادامه مقاله، بیشتر با این ابزار جالب و کاربردی آشنا می شویم.
پایگاه داده چیست؟
در محاسبات، پایگاه داده مجموعه ای سازمان یافته از داده هایی است که به صورت الکترونیکی ذخیره شده و قابل دسترسی هستند.
پایگاه داده های کوچک را می توان در یک سیستم فایل ذخیره کرد، در حالی که پایگاه های داده بزرگ روی خوشه های کامپیوتری یا فضای ذخیره سازی ابری میزبانی می شوند. طراحی پایگاههای داده شامل تکنیکهای رسمی و ملاحظات عملی از جمله مدلسازی داده، نمایش و ذخیره کارآمد دادهها، زبانهای کوئری، امنیت دادهها، و مسائل محاسباتی توزیعشده مانند دسترسی همزمان و تحمل خطا هستند.
سیستم مدیریت پایگاه داده یا DBMS نرم افزاری است که با کاربران نهایی، برنامه ها و خود پایگاه داده برای جمع آوری و تجزیه و تحلیل داده ها در تعامل است. DBMS مخفف عبارت Database Management System است که ترجمه آن به زبان فارسی می شود: سامانه مدیریت پایگاه داده. نرم افزار DBMS علاوه بر این، امکانات اصلی ارائه شده برای مدیریت پایگاه داده را در بر می گیرد. مجموع کل پایگاه داده، DBMS و برنامه های کاربردی مرتبط را می توان به عنوان یک سیستم پایگاه داده نام برد. معمولا اصطلاح «پایگاه داده» برای اشاره به هر یک از DBMS ها، سیستم پایگاه داده یا برنامه های کاربردی مرتبط با پایگاه داده نیز استفاده می شود.
دانشمندان علوم رایانه ممکن است سیستم های مدیریت پایگاه داده را بر اساس مدل های پایگاه داده ای که از آن ها پشتیبانی می کنند، طبقه بندی کنند. پایگاه داده های رابطه ای در دهه 1980 قدرتمند شدند. این داده ها را به صورت ردیف و ستون در یک سری جدول ها مدل می کنند و بیش تر آن ها از SQL برای نوشتن و کوئری کردن داده ها استفاده می کنند. در دهه 2000، پایگاههای داده غیررابطهای رایج شدند که به نام NoSQL شناخته میشوند، زیرا از زبانهای کوئری مختلفی استفاده میکنند.

نقش دیتابیس در وبسایت ها
می توان به جرأت گفت که تمام وبسایت ها و اپلیکیشن های مدرن از یک دیتابیس برای مدیریت و ذخیره اطلاعاتشان استفاده می کنند. برای مثال وبسایت روکسو برای نمایش دوره های آموزشی خود به کاربران از یک جدول دیتابیس استفاده می کند که در این دیتابیس مقادیر مختلفی ذخیره سازی و سپس در صفحه ای مخصوص به کاربران نمایش داده می شود.

برای درک بهتر این موضوع چند مورد از مقادیری را که وبسایت روکسو برای هر دوره آموزشی خود در نظر می گیرد، مثال میزنم:
-
- نام دوره آموزشی
- قیمت دوره آموزشی
- جلسات و فایل های دوره
- مدرس دوره آموزشی
- دسته بندی و موضوع
- توضیحات و....
نکته: این اطلاعات صرفا برای درک بهتر مفهوم پایگاه داده بود و ارتباط مشخصی با پایگاه داده وبسایت روکسو ندارد!
مشاهده کردید که وبسایت آموزشی روکسو برای هر دوره آموزشی که قرار است منتشر شود، اطلاعات مشخصی را در نظر گرفته است و در صورتی که قرار باشد یک دوره آموزشی جدید در این سایت برگزار شود، لازم است مشخصات آن دوره طبق مقادیری که در این جدول تعریف شده است در پایگاه داده ذخیره سازی شود.

مفهوم جدول (Table) در دیتابیس
هر پایگاه داده ای که ایجاد می شود شامل جداول مختلف و متعددی است. در مثال بالا ما اشاره کردیم که سایت روکسو برای دوره های آموزشی خود یک جدول به عنوان دوره های آموزشی ایجاد کرده است و اطلاعات مختلفی را در آن ذخیره می کند. در همین وبسایت برای لیست کاربران یک جدول دیگر موجود است و همچنین برای مقالات سایت، جدول دیگری تعبیه شده است.
مفهوم ستون و ردیف در جداول
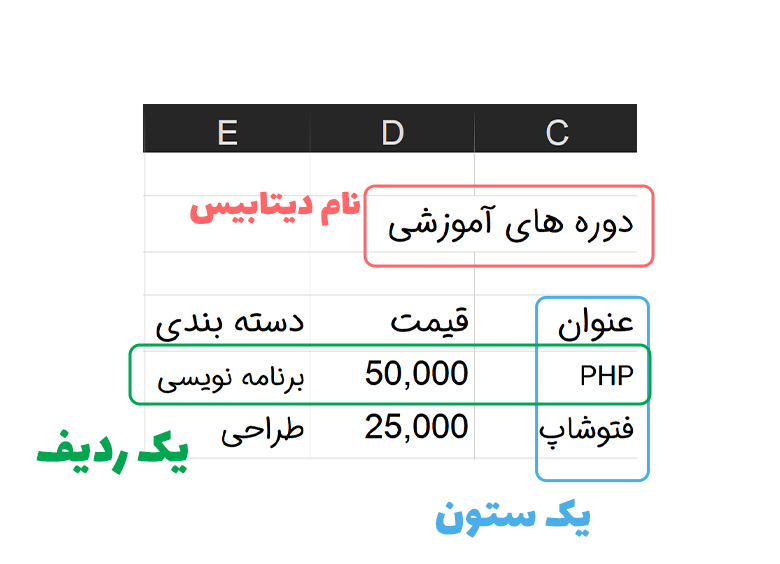
هر جدول که در پایگاه داده موجود است دارای چندین ستون و ردیف می باشد.
منظور از ستون، فیلدهایی است که ما به عنوان ورودی برای هر جدول تعیین کرده ایم. برای مثال برای جدول دوره های آموزشی در سایت روکسو ستون های «عنوان دوره»، «مبلغ دوره»، «توضیحات» و... تعیین شده اند.
منظور از ردیف، مقادیری است که به عنوان یک سطر وارد دیتابیس می شوند. برای مثال در جدول دوره های آموزشی سایت روکسو، مشخصات هر دوره آموزشی که به این جدول افزوده می شود ردیف نام دارد.

معروف ترین نرم افزارهای سیستم مدیریت پایگاه داده عبارتند از:
- MySQL
- Microsoft Access
- Oracle
- PostgreSQL
- dBASE
- FoxPro
- SQLite
- IBM DB2
- LibreOffice Base
- MariaDB
- Microsoft SQL Server
اصطلاحات و مرور کلی
به طور رسمی، «پایگاه داده» به مجموعه ای از داده های مرتبط و روش سازماندهی آن ها اشاره دارد. دسترسی به این داده ها معمولا توسط یک «سیستم مدیریت پایگاه داده» یا همان «DBMS» که متشکل از مجموعه ای یکپارچه از نرم افزارهای کامپیوتری است می شود و به کاربران اجازه می دهد با یک یا چند پایگاه داده تعامل داشته باشند و دسترسی به تمام داده های موجود در پایگاه داده را فراهم می کند (اگرچه ممکن است محدودیت هایی وجود داشته باشد که دسترسی به داده های خاص را محدود کند). DBMS عملکردهای مختلفی را فراهم می کند که اجازه ورود، ذخیره سازی و بازیابی مقادیر زیادی از اطلاعات را می دهد و راه هایی را برای مدیریت و نحوه سازماندهی آن اطلاعات ارائه می دهد.
به دلیل همانندی نزدیک پایگاه داده و DBMS ممکن است سردرگمی و ابهام ایجاد شود. اصطلاح «پایگاه داده» برای اشاره به یک پایگاه داده و اصطلاح DBMS برای دستکاری آن استفاده می شود.
DBMS های موجود توابع مختلفی دارند که امکان مدیریت پایگاه داده و داده های آن را فراهم می کند. این توابع را می توان به چهار گروه اصلی طبقه بندی کرد:
تعریف داده – ایجاد، ویرایش و حذف تعاریفی که ساختار داده ها را تعریف می کنند.
ویرایش - درج، ویرایش، و حذف داده های واقعی.
بازیابی - ارائه اطلاعات به شکلی که مستقیما یا برای پردازش بیش تر توسط سایر برنامه ها قابل استفاده است. داده های بازیابی شده ممکن است به همان شکلی است که در پایگاه داده ذخیره شده اند یا به شکل جدیدی که با تغییر یا ترکیب داده های موجود از پایگاه داده به دست آمده است، در دسترس قرار گیرند.
مدیریت - ثبت و نظارت بر کاربران، اعمال امنیت داده ها، نظارت بر عملکرد، حفظ یکپارچگی داده ها، برخورد با کنترل همزمان، و بازیابی اطلاعاتی که توسط برخی رویدادها مانند خرابی غیرمنتظره سیستم خراب شده است.
هم یک پایگاه داده و هم DBMS آن با اصول یک مدل پایگاه داده خاص مطابقت دارند. «سیستم پایگاه داده» در مجموع به مدل پایگاه داده، سیستم مدیریت پایگاه داده و پایگاه داده اشاره دارد.
از نظر فیزیکی، سرورهای پایگاه داده، رایانههای ویژه ای هستند که پایگاههای داده واقعی را نگهداری میکنند و فقط DBMS و نرمافزارهای مرتبط را اجرا میکنند. سرورهای پایگاه داده معمولا رایانه های چند پردازنده ای هستند، با حافظه زیاد و آرایه های دیسک RAID برای ذخیره سازی پایدار استفاده می شود. شتاب دهنده های پایگاه داده سخت افزاری که از طریق یک کانال پرسرعت به یک یا چند سرور متصل می شوند، در محیط های پردازش تراکنش های با حجم بالا نیز استفاده می شوند. DBMS ها در قلب بیش تر برنامه های کاربردی پایگاه داده یافت می شوند. DBMS ها ممکن است حول یک هسته چندوظیفه ای سفارشی با پشتیبانی شبکه داخلی ساخته شوند، اما DBMS های مدرن معمولا برای ارائه این عملکردها به یک سیستم عامل استاندارد متکی هستند.
پایگاه های داده و DBMS ها را می توان بر اساس مدل های پایگاه داده ای که پشتیبانی می کنند مانند رابطه ای یا XML، نوع کامپیوتری که روی آن اجرا می شوند (از خوشه سرور گرفته تا تلفن همراه)، زبان کوئری کردن برای دسترسی به پایگاه داده مانند SQL یا XQuery و مهندسی داخلی آن ها استفاده می شود که بر عملکرد، مقیاس پذیری، انعطاف پذیری و امنیت تاثیر می گذارد.
تاریخچه
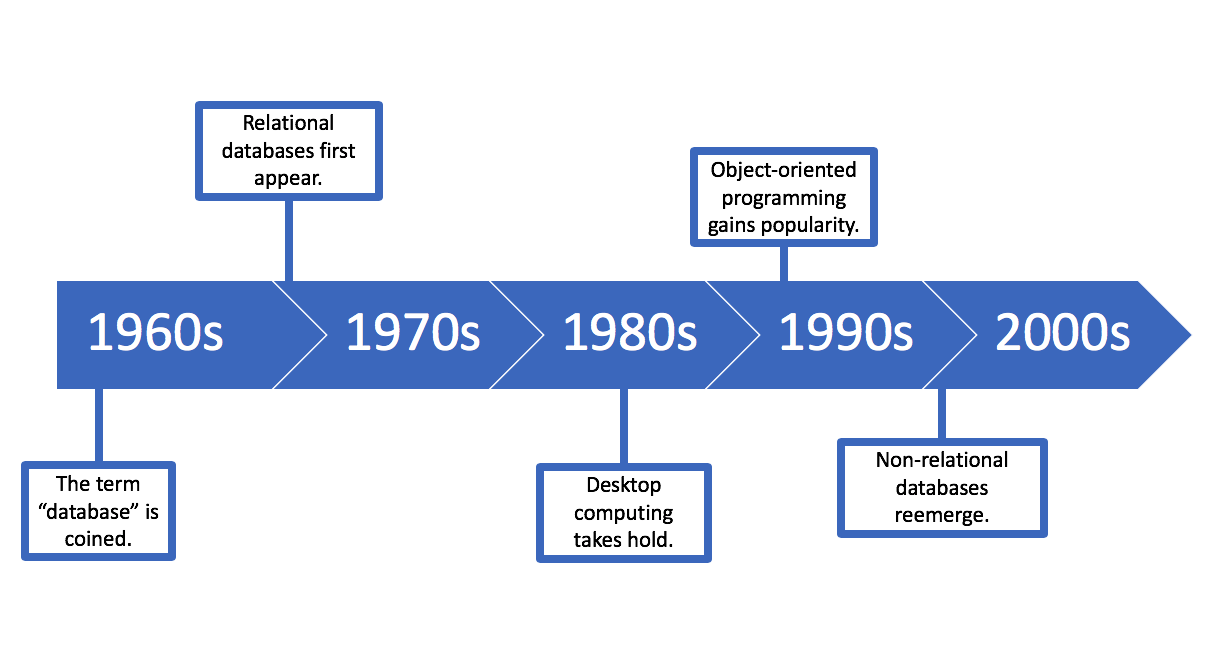
اندازهها، توانمندی ها و عملکرد پایگاههای داده و DBMS مربوط به آنها رشد زیادی داشته اند. این افزایش عملکرد با پیشرفت فناوری در زمینه پردازنده ها، حافظه رایانه، ذخیره سازی رایانه و شبکه های رایانه ای امکان پذیر شد. مفهوم پایگاه داده با ظهور رسانه های ذخیره سازی مانند دیسک های مغناطیسی که در اواسط دهه 1960 به طور گسترده در دسترس قرار گرفت، ممکن شد. سیستم های قبلی به ذخیره سازی متوالی داده ها روی نوار مغناطیسی متکی بودند. پیشرفت های بعدی فناوری پایگاه داده را می توان بر اساس مدل یا ساختار داده به سه دوره تقسیم کرد:
- ناوبری (navigational)
- SQL / رابطه ای (SQL/relational)
- پسا رابطه ای (post-relational)
دو مدل اصلی ناوبری داده ها، مدل سلسله مراتبی و مدل CODASYL که به آن مدل شبکه می گویند، بودند. آن ها با استفاده از نشانگرها (اغلب آدرسهای دیسک فیزیکی) برای دنبال کردن روابط از یک رکورد به رکورد دیگر مشخص میشوند.
مدل رابطهای که برای اولین بار در سال 1970 توسط ادگار اف. کاد ارائه شد، با تکیه بر این که برنامهها باید به جای دنبال کردن پیوندها، دادهها را بر اساس محتوا جستجو کنند، از روش قدیمی فاصله گرفت. مدل رابطهای از مجموعههایی از جدول ها استفاده می کند. در اواسط دهه 1980، سخت افزار محاسباتی به اندازه کافی قدرتمند شد که امکان استقرار گسترده سیستم های رابطه ای (DBMS ها به علاوه برنامه های کاربردی) را فراهم آورد. با این حال، در اوایل دهه 1990، سیستمهای رابطهای برهمه برنامههای پردازش داده در مقیاس بزرگ تسلط داشتند، و از سال 2018 نیز این روند برای IBM DB2، Oracle، MySQL و Microsoft SQL Server ادامه دارد و بیش ترین جستجوی DBMS را دارا ی باشند.
پایگاه داده های شی ای در دهه 1980 برای غلبه بر سختی هایی که تطابق نداشتن امپدانس شی-رابطه ای ایجاد می کردند، توسعه یافتند، که منجر به وجود آمدن اصطلاح «پسا رابطه ای» و هم چنین توسعه پایگاه های داده ترکیبی شی-رابطه ای شد.
نسل بعدی پایگاههای داده پسا رابطهای در اواخر دهه 2000 به نام پایگاههای داده NoSQL شناخته شد و store های کلید-مقدار و پایگاههای داده سندگرا را معرفی کرد. نسل بعدی پایگاههای داده معروف به پایگاههای داده NewSQL، پیادهسازیهای جدیدی را انجام داد که مدل رابطهای/SQL را حفظ کرد، در حالی که هدف آن مطابقت با عملکرد بالای NoSQL در مقایسه با DBMSهای رابطهای تجاری موجود بود.
در زیر تاریخچه پایگاه داده ها را در دهه های مختلف بررسی می کنیم.
دهه 1960، DBMS ناوبری
معرفی اصطلاح پایگاه داده همزمان با در دسترس بودن فضای ذخیره سازی با دسترسی مستقیم (دیسک و درام) از اواسط دهه 1960 به بعد بود. این اصطلاح نشاندهنده تضاد با سیستمهای مبتنی بر نوار در گذشته بود و به جای پردازش دستهای روزانه، امکان استفاده تعاملی مشترک را میداد.
با افزایش سرعت و توانایی کامپیوترها، سیستم های پایگاه داده همه منظوره ظهور کردند. در اواسط دهه 1960 تعدادی از این سیستم ها به صورت تجاری مورد استفاده قرار گرفتند. در سال 1971، گروه توسعه دهنده استاندارد خود را ارائه کرد که با نام رویکرد CODASYL شناخته شد و خیلی سریع تعدادی از محصولات تجاری مبتنی بر این رویکرد وارد بازار شدند.
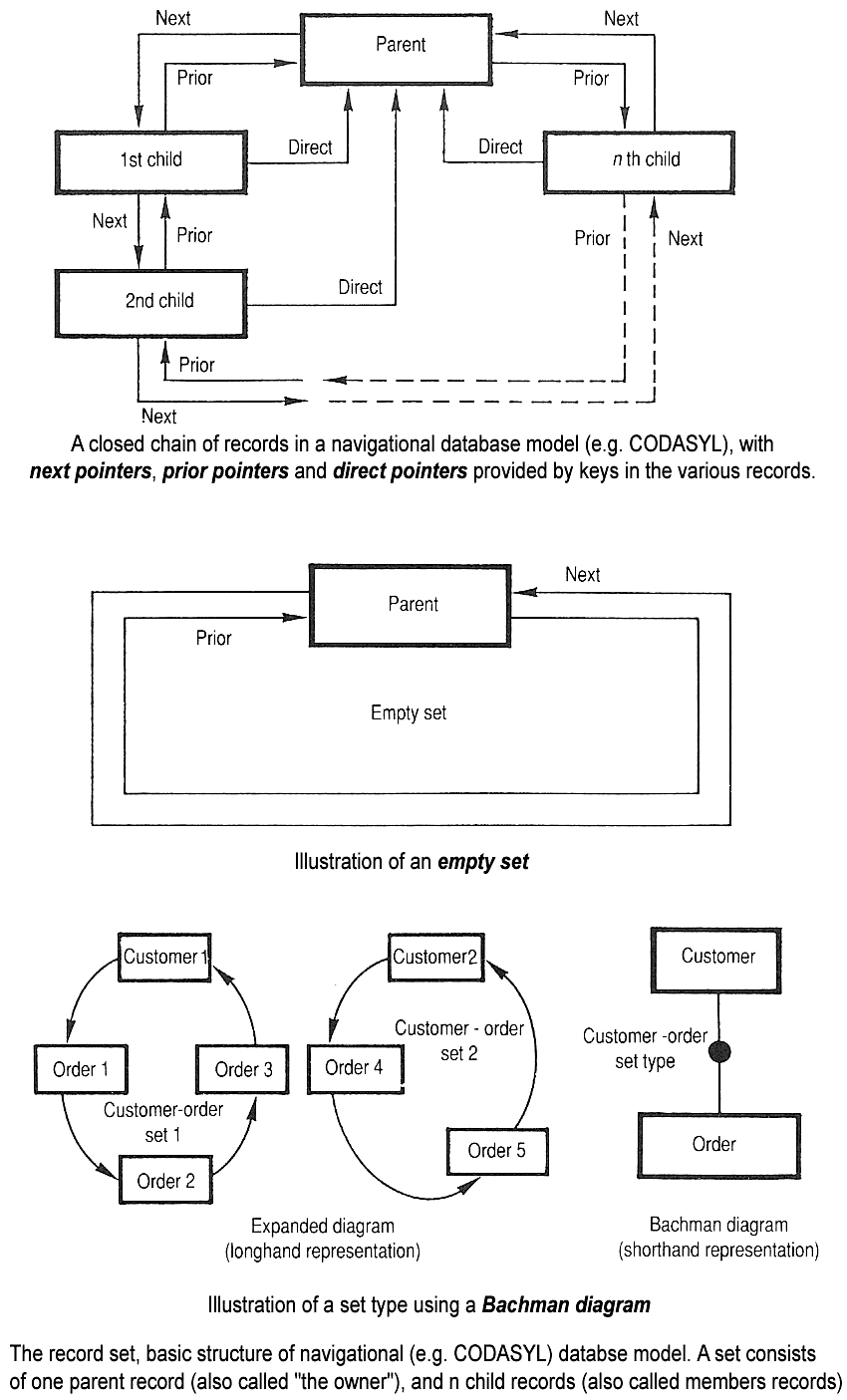
رویکرد CODASYL به برنامههای کاربردی این امکان را میدهد تا در پیرامون دادههای پیوندی که به یک شبکه بزرگ تبدیل شده اند، حرکت کنند. برنامه ها می توانند رکوردها را با یکی از سه روش پیدا کنند:
- استفاده از یک کلید اصلی (معروف به کلید CALC که معمولا با هش کردن اجرا می شود)
- پیمایش روابط (به نام set) از یک رکورد به رکورد دیگر
- پیمایش همه رکوردها به ترتیب متوالی
سیستمهای بعدی B-trees را برای ارائه مسیرهای دسترسی جایگزین اضافه کردند. بسیاری از پایگاه های داده CODASYL هم چنین یک زبان کوئری تعریفی را برای کاربران نهایی اضافه کردند. با این حال پایگاه های داده CODASYL پیچیده بودند و نیاز به آموزش و تلاش زیادی برای تولید برنامه های کاربردی مفید داشتند.
IBM هم چنین در سال 1966 DBMS خود را داشت که به سیستم مدیریت اطلاعات IMS معروف بود. IMS توسعه نرم افزاری بود که برای برنامه Apollo در System/360 نوشته شده بود. IMS از نظر مفهومی مشابه CODASYL بود، اما به جای مدل شبکه CODASYL از یک سلسله مراتب دقیق برای مدل ناوبری داده خود استفاده کرد. هر دو مفهوم بعدا به دلیل نحوه دسترسی به داده ها به عنوان پایگاه داده های ناوبری شناخته شدند. این اصطلاح با ارائه جایزه تورینگ در سال 1973 توسط باخمن ناوبر رایج شد. IMS توسط IBM به عنوان یک پایگاه داده سلسله مراتبی طبقه بندی شده است. پایگاه داده TOTAL IDMS و Cincom Systems به عنوان پایگاه داده شبکه طبقه بندی می شوند. IMS از سال 2014 هم چنان در حال استفاده است.
دهه 1970، DBMS رابطه ای
«ادگار اف کاد» در IBM در سن خوزه، کالیفرنیا، در یکی از دفاتر فرعی آن ها که در توسعه سیستمهای دیسک سخت شرکت داشت، کار میکرد. او از مدل ناوبری رویکرد CODASYL ناراضی بود، به ویژه این که این مدل یک مرکز "جستجو" نداشت. در سال 1970، او مقاله هایی نوشت که یک رویکرد جدید برای ساخت پایگاه داده را نشان می داد که در نهایت با مدل پیشگامانه A Relational Data for Large Data Banks به اوج رسید.
وی در این مقاله سیستم جدیدی را برای ذخیره سازی و کار با پایگاه های داده بزرگ تشریح کرد. به جای این که رکوردها در نوعی لیست پیوندی از رکوردهای free-form مانند CODASYL ذخیره شوند، ایده کاد این بود که داده ها را به صورت تعدادی "جدول" سازماندهی کنند، که هر جدول برای نوع متفاوتی از موجودیت استفاده می شود. هر جدول شامل تعداد ثابتی از ستونها میشود که دارای ویژگیهای موجودیت است. یک یا چند ستون از هر جدول بهعنوان کلید اصلی تعیین میشد که به این ترتیب ردیفهای جدول را میتوان بهطور منحصربهفرد شناسایی کرد.
ارجاعات متقابل بین جدول ها همیشه از این کلیدهای اصلی به جای آدرسهای دیسک استفاده میکردند، و کوئری ها براساس این روابط کلیدی، با استفاده از مجموعهای از عملیات بر اساس سیستم ریاضی محاسبات رابطهای (که نام مدل از آن گرفته شده است) به جدول ها میپیوندند. هدف تقسیم داده ها به مجموعه ای از جدول ها (یا روابط) نرمال شده، اطمینان از این که هر "fact" فقط یک بار ذخیره می شود، در نتیجه عملیات به روز رسانی را ساده می کند. جدول های مجازی به نام view میتوانند دادهها را به روشهای مختلف برای کاربران مختلف ارائه کنند، اما view ها را نمیتوان مستقیما بهروزرسانی کرد.
Codd از اصطلاحات ریاضی برای تعریف مدل استفاده کرد. روابط، تاپل ها و دامنه ها به جای جداول، ردیف ها و ستون ها. اصطلاحی که در حال حاضر آشناست از پیاده سازی های اولیه آمده است. کاد بعدا از تمایل پیادهسازیهای عملی به انحراف از مبانی ریاضی که مدل بر آن بنا شده بود انتقاد کرد.
استفاده از کلیدهای اصلی (شناسه های کاربر محور) برای نشان دادن روابط متقابل جدول، به جای آدرس های دیسک، دو انگیزه اصلی داشت. از منظر مهندسی، جدول ها را قادر می سازد بدون سازماندهی مجدد پایگاه داده جابجا شده و اندازه آن ها تغییر کند
در مدل های سلسله مراتبی و شبکه، رکوردها اجازه داشتند ساختار داخلی پیچیده ای داشته باشند. در مدل رابطهای، فرآیند عادیسازی منجر به این شد که چنین ساختارهای داخلی با دادههایی که در جدول های متعدد نگهداری میشوند، جایگزین شوند، که فقط با کلیدهای منطقی به هم متصل میشوند.
علاوه بر شناسایی سطرها/رکوردها با استفاده از شناسههای منطقی به جای آدرسهای دیسک، Codd روشی را به وجود آورد که در آن برنامهها دادهها را از چندین رکورد جمعآوری میکردند. بهجای این که برنامهها نیاز به جمعآوری دادهها در یک رکورد داشته باشند، از یک زبان کوئری تعریفی استفاده میکنند که بیان میکند چه دادهای مورد نیاز است، نه مسیر دسترسی که باید توسط آن پیدا شود. یافتن یک مسیر دسترسی کارآمد به عهده سیستم مدیریت پایگاه داده قرار گرفت. این فرآیند که بهینه سازی کوئری نامیده می شود به این واقعیت بستگی دارد که پرس و جوها بر اساس منطق ریاضی بیان می شوند.
آیبیام یک اجرای آزمایشی از مدل رابطهای، PRTV، و یک آزمایش تولیدی، Business System 12 را انجام داد که هر دو اکنون متوقف شدهاند. Honeywell MRDS را برای Multics نوشت و اکنون دو پیاده سازی جدید وجود دارد: Alphora و Dataphor. Rel بیش تر پیاده سازی های دیگر DBMS که معمولا رابطه ای نامیده می شوند در واقع DBMS های SQL هستند.
رویکرد یکپارچه
در دهه های 1970 و 1980 تلاش هایی برای ساخت سیستم های پایگاه داده با سخت افزار و نرم افزار یکپارچه صورت گرفت. فلسفه اساسی این بود که چنین ادغامی عملکرد بالاتری را با هزینه کمتر ارائه می دهد. به عنوان مثال، IBM System/38، ارائه اولیه Teradata، و ماشین پایگاه داده Britton Lee, Inc.
رویکرد دیگر برای پشتیبانی سخت افزاری برای مدیریت پایگاه داده، شتاب دهنده CAFS ICL، یک کنترل کننده دیسک سخت افزاری با قابلیت جستجوی قابل برنامه ریزی بود. در درازمدت، این تلاشها عموما ناموفق بودند، زیرا ماشینهای پایگاهداده تخصصی نمیتوانستند همگام با توسعه و پیشرفت سریع رایانههای همه منظوره باشند. بنابراین بیش تر سیستم های پایگاه داده امروزه سیستم های نرم افزاری هستند که بر روی سخت افزار همه منظوره اجرا می شوند و از ذخیره سازی داده های کامپیوتری همه منظوره استفاده می کنند. با این حال، این ایده هنوز برای برنامه های خاص توسط برخی از شرکت ها مانند Netezza و Oracle (Exadata) دنبال می شود.
اواخر دهه 1970، SQL DBMS
IBM در اوایل دهه 1970 شروع به کار بر روی یک سیستم نمونه اولیه کرد که کاملا مبتنی بر مفاهیم Codd به عنوان System R بود. اولین نسخه در سال 1974/5 آماده شد و سپس کار بر روی سیستم های چند جدولی شروع شد که در آن داده ها می توانستند به گونه ای تقسیم شوند که تمام داده های یک رکورد (که برخی از آنها اختیاری است) لازم نباشد در یک "chunk" ذخیره شوند.
پایگاه داده اوراکل لری الیسون یا اوراکل بر اساس مقالات IBM در مورد System R شروع به کار کرد.
Stonebraker در ادامه درسهای INGRES، را برای توسعه پایگاه داده جدید Postgres که اکنون به عنوان PostgreSQL شناخته میشود، به کار برد. PostgreSQL اغلب برای برنامه های کاربردی استفاده می شود.
در سوئد، مقاله Codd نیز خوانده شد و Mimer SQL از اواسط دهه 1970 در دانشگاه اوپسالا توسعه یافت. در سال 1984، این پروژه به یک شرکت مستقل تجمیع شد.
مدل داده دیگری، مدل نهاد-رابطه، در سال 1976 پدیدار شد و برای طراحی پایگاه داده محبوبیت یافت زیرا بر توصیف بهتر از مدل رابطهای تاکید داشت.
دهه 1980
دهه 1980 عصر رایانش دسکتاپ آغاز شد. کامپیوترهای جدید با صفحات گسترده مانند Lotus 1-2-3 و نرم افزار پایگاه داده مانند dBASE به کاربران خود قدرت دادند. محصول dBASE سبک وزن بود و برای هر کاربر کامپیوتری به راحتی قابل درک بود. دستکاری داده ها به جای این که توسط dBASE انجام شود، توسط dBASE انجام می شود. بنابراین کاربر میتواند روی کاری که انجام میدهد تمرکز کند، به جای این که مجبور باشد با جزئیاتی مانند باز کردن، خواندن و بستن فایلها و مدیریت تخصیص فضا درگیر شود. dBASE یکی از پرفروشترین عنوانهای نرمافزاری در دهه 1980 و اوایل دهه 1990 بود.
دهه 1990
دهه 1990، همراه با گسترش برنامه نویسی شی گرا، رشد در نحوه مدیریت داده ها در پایگاه های داده ها نیز به وجود آمد. برنامه نویسان و طراحان با داده های پایگاه داده خود به عنوان اشیا برخورد کردند. به این معنا که اگر داده های یک فرد در یک پایگاه داده بود، ویژگی های آن شخص، مانند آدرس، شماره تلفن و سن، به جای داده های اضافی، اکنون متعلق به آن شخص در نظر گرفته می شود. این اجازه می دهد تا روابط بین داده ها، روابطی با اشیا و ویژگی های آن ها باشد و نه به فیلدهای تنها. پایگاه داده های شی و پایگاه داده های شی-رابطه ای سعی در حل این مشکل با ارائه یک زبان شی گرا که برنامه نویسان می توانند از آن به عنوان جایگزینی برای SQL صرفا رابطه ای استفاده کنند.
دهه 2000، NoSQL و NewSQL
پایگاه داده های XML نوعی پایگاه داده ساختاریافته سندگرا هستند که امکان کوئری را بر اساس ویژگی های سند XML فراهم می کند. پایگاههای داده XML بیش تر در برنامههایی استفاده میشوند که دادهها به راحتی به عنوان مجموعهای از اسناد مشاهده میشوند، با ساختاری که میتواند بسیار انعطافپذیر تا بسیار پیچیده متفاوت باشد.
پایگاههای داده NoSQL بسیار سریع هستند، به طرحوارههای (schema های) جدول ثابت نیاز ندارند، از عملیات پیوستن با ذخیره دادههای غیرعادیشده دوری میکنند.
در سالهای اخیر، درخواست های زیادی برای پایگاههای داده با توزیع انبوه با تحمل پارتیشن بالا وجود داشته است، اما طبق قضیه CAP، برای یک سیستم توزیع شده غیرممکن است که به طور همزمان، پایداری، در دسترس بودن و تحمل پارتیشن را ارائه دهد. یک سیستم توزیع شده می تواند هر دو مورد از این ضمانت ها را همزمان برآورده کند، اما نه هر سه را. به همین دلیل، بسیاری از پایگاههای داده NoSQL از آن چه سازگاری نهایی نامیده میشود برای ارائه تضمینهای در دسترس بودن و تحمل پارتیشن با سطح پایینتری از سازگاری داده استفاده میکنند.
NewSQL یک کلاس از پایگاههای داده رابطهای مدرن است که هدف آن ارائه عملکرد مقیاسپذیر سیستمهای NoSQL برای بارهای کاری پردازش تراکنش آنلاین (خواندن-نوشتن) است، در حالی که هم چنان از SQL استفاده میکند و تضمینهای ACID یک سیستم پایگاه داده سنتی را حفظ میکند.
کاربردهای پایگاه داده

پایگاه های داده برای پشتیبانی از عملیات داخلی سازمان ها و برای تقویت تعاملات آنلاین با مشتریان و تامین کنندگان استفاده می شود. پایگاه های داده برای نگهداری اطلاعات اداری و داده های تخصصی تر، مانند داده های مهندسی یا مدل های اقتصادی استفاده می شود. به عنوان مثال می توان به سیستم های کتابخانه کامپیوتری، سیستم های رزرو پرواز، سیستم های موجودی قطعات کامپیوتری و بسیاری از سیستم های مدیریت محتوا اشاره کرد که وب سایت ها را به عنوان مجموعه ای از صفحات وب در یک پایگاه داده ذخیره می کنند.
طبقه بندی پایگاه داده ها
یکی از راههای طبقهبندی پایگاههای داده براساس نوع محتویات آنها است، بهعنوان مثال: اشیا document-text یا اشیا آماری یا چند رسانهای. راه دیگر بر اساس حوزه کاربرد آن ها است، به عنوان مثال: حسابداری، آهنگسازی، فیلم، بانکداری، تولید یا بیمه و غیره. راه سوم، برخی جنبه های فنی، مانند ساختار پایگاه داده یا نوع رابط است. این بخش تعدادی از صفت هایی را که برای توصیف انواع مختلف پایگاه های داده استفاده می شود، فهرست می کند.
- یک پایگاه داده in-memory، پایگاه داده ای است که عمدتا در حافظه اصلی قرار دارد، اما معمولا توسط ذخیره سازی داده های رایانه ای پشتیبان گیری می شود. پایگاه دادههای حافظه اصلی سریعتر از پایگاههای داده دیسک هستند، و بنابراین اغلب در جاهایی که زمان پاسخدهی حیاتی است، مانند تجهیزات شبکههای مخابراتی، استفاده میشوند.
- یک پایگاه داده فعال شامل یک معماری رویداد محور است که می تواند به شرایط داخلی و خارجی پایگاه داده پاسخ دهد. کاربردهای احتمالی شامل نظارت امنیتی، هشدار، جمع آوری آمار و مجوزها می باشد. بسیاری از پایگاه های داده ویژگی های پایگاه داده فعال را در قالب محرک های پایگاه داده ارائه می کنند.
- پایگاه داده ابری متکی بر فناوری ابری است. هم پایگاه داده و هم بیش تر DBMS های آن از راه دور، "در فضای ابری" قرار دارند، در حالی که برنامه های کاربردی آن هر دو توسط برنامه نویسان توسعه داده می شوند و بعدا توسط کاربران نهایی از طریق مرورگر وب و Open API نگهداری و استفاده می شوند.
- انبارهای داده، داده ها را از پایگاه های داده عملیاتی و معمولا از منابع خارجی بایگانی می کنند. انبار منبع اصلی داده برای استفاده مدیران و سایر کاربران نهایی است که ممکن است به داده های عملیاتی دسترسی نداشته باشند. برخی از اجزای اساسی و ضروری انبار داده شامل استخراج، تجزیه و تحلیل و استخراج داده ها، تبدیل، بارگذاری و مدیریت داده ها به منظور در دسترس قرار دادن آن ها برای استفاده بیش تر است.
- یک پایگاه داده قیاسی برنامه نویسی منطقی را با پایگاه داده رابطه ای ترکیب می کند.
- پایگاه داده توزیع شده پایگاهی است که در آن داده ها و DBMS چندین کامپیوتر را در بر می گیرند.
- یک پایگاه داده سند گرا برای ذخیره، بازیابی و مدیریت اطلاعات document یا اطلاعات نیمه ساختار یافته طراحی شده است. پایگاه داده های سند گرا یکی از دسته های اصلی پایگاه های داده NoSQL هستند.
- یک سیستم پایگاه داده تعبیه شده (embeded) یک DBMS است که به شدت با یک نرم افزار کاربردی یکپارچه شده است و نیاز به تعمیر و نگهداری کم داشته باشد.
- پایگاههای داده هایEnd-user شامل دادههایی است که توسط کاربران نهایی ایجاد شدهاند. نمونههایی از این موارد مجموعهای از document ها، صفحات گسترده ، چند رسانهای ها و فایلهای دیگر است.
- یک سیستم پایگاه داده متحد (federate) شامل چندین پایگاه داده مجزا است که هر کدام دارای DBMS خاص خود هستند. این به عنوان یک پایگاه داده واحد توسط یک سیستم مدیریت پایگاه داده FDBMS مدیریت می شود، که به طور شفاف چندین DBMS مستقل، احتمالا از انواع مختلف (در این صورت یک سیستم پایگاه داده ناهمگن نیز خواهد بود) را یکپارچه می کند و یک نمای مفهومی یکپارچه را برای آن ها فراهم می کند.
- گاهی اوقات اصطلاح پایگاه داده چندتایی با پایگاه داده متحد یکی درنظر گرفته می شود، اگرچه ممکن است به یک گروه پایگاه داده کمتر یکپارچه (به عنوان مثال، بدون FDBMS و طرح یکپارچه مدیریت شده) اشاره کند که در یک برنامه از آن ها استفاده می شود.
- پایگاه داده گراف نوعی پایگاه داده NoSQL است که از ساختارهای گراف با گره ها، یال ها و ویژگی ها برای نمایش و ذخیره اطلاعات استفاده می کند. پایگاههای اطلاعاتی گراف عمومی که میتوانند هر گرافی را ذخیره کنند، از پایگاههای داده گراف تخصصی مانند triplestores و پایگاههای داده شبکه متمایز هستند.
- یک DBMS آرایه ای نوعی از NoSQL DBMS است که امکان مدل سازی، ذخیره سازی و بازیابی آرایه های چند بعدی مانند تصاویر ماهواره ای و خروجی شبیه سازی آب و هوا را فراهم می کند.
- در یک پایگاه داده ابرمتن یا ابررسانه، هر کلمه یا قطعه ای از متن که یک شی را نشان می دهد، به عنوان مثال، یک قطعه متن دیگر، یک مقاله، یک تصویر یا یک فیلم، می تواند به آن شی پیوند داده شود. پایگاه داده های فرامتن به ویژه برای سازماندهی مقادیر زیادی از اطلاعات متفاوت مفید هستند. به عنوان مثال، آنها برای سازماندهی دایره المعارف های آنلاین مفید هستند، جایی که کاربران می توانند در متن ها جستجو کنند. بنابراین شبکه جهانی وب یک پایگاه داده فرامتن توزیع شده بزرگ است.
- پایگاه دانش نوع خاصی از پایگاه داده برای مدیریت دانش است که ابزار جمع آوری کامپیوتری، سازماندهی و بازیابی دانش را فراهم می کند. هم چنین مجموعه ای از داده ها که مشکلات را با راه حل ها و تجربیات مرتبط نشان می دهد.
- یک پایگاه داده تلفن همراه را می توان روی یک دستگاه محاسباتی سیار حمل یا همگام سازی کرد.
- پایگاه های داده عملیاتی داده های دقیق در مورد عملیات یک سازمان را ذخیره می کنند. آن ها معمولا حجم نسبتا بالایی از به روز رسانی ها را با استفاده از تراکنش ها پردازش می کنند. به عنوان مثال میتوان به پایگاههای اطلاعاتی مشتریان که اطلاعات تماس، اعتبار و جمعیتشناختی مشتریان یک کسبوکار را ثبت میکند، پایگاههای اطلاعاتی پرسنلی که اطلاعاتی مانند حقوق، مزایا، دادههای مهارتها در مورد کارکنان را در خود نگه میدارد، سیستمهای برنامهریزی منابع سازمانی که جزئیات مربوط به اجزای محصول، موجودی قطعات، و مالی را ثبت میکنند و پایگاه های داده ای که پول، حسابداری و معاملات مالی سازمان را پیگیری می کند.
- یک پایگاه داده موازی به دنبال بهبود عملکرد از طریق موازی سازی برای کارهایی مانند بارگذاری داده ها، ساختن اندیس ها و ارزیابی کوئری ها است.
- معماریهای DBMS موازی اصلی که توسط معماری سختافزاری ایجاد میشوند عبارتند از:
- معماری حافظه مشترک، که در آن چندین پردازنده فضای اصلی حافظه و هم چنین سایر ذخیره سازی داده ها را به اشتراک می گذارند.
- معماری دیسک مشترک، که در آن هر واحد پردازشی (معمولا از چندین پردازنده تشکیل شده است) حافظه اصلی خود را دارد، اما همه واحدها در فضای ذخیره سازی دیگر مشترک هستند.
- معماری اشتراکگذاری هیچ، که در آن هر واحد پردازش حافظه اصلی و ذخیرهسازی دیگر خود را دارد.
- پایگاه داده های احتمالی از منطق فازی برای استنتاج از داده های نادقیق استفاده می کنند.
- پایگاههای داده بیدرنگ، تراکنشها را بهقدری سریع پردازش میکنند که نتیجه بازگردد و فورا به آن عمل شود.
- یک پایگاه داده فضایی می تواند داده ها را با ویژگی های چند بعدی ذخیره کند. پرسشهای مربوط به چنین دادههایی شامل پرسشهای مبتنی بر مکان، مانند "نزدیکترین هتل در منطقه من کجاست؟" است.
- یک پایگاه داده زمانی دارای جنبه های زمانی داخلی است، به عنوان مثال یک مدل داده زمانی و یک نسخه زمانی SQL. به طور خاص، جنبه های زمانی معمولا شامل valid-time و transaction-time است.
- یک پایگاه داده اصطلاح گرا بر پایه یک پایگاه داده شی گرا ساخته می شود که اغلب برای یک زمینه خاص سفارشی می شود.
- یک پایگاه داده بدون ساختار در نظر گرفته شده است تا اشیا متنوعی را که به طور طبیعی و راحت در پایگاه های داده رایج قرار نمی گیرند، به روشی قابل مدیریت و محافظت شده ذخیره کند. ممکن است شامل پیامهای ایمیل و غیره باشد. این نام ممکن است گمراهکننده باشد زیرا برخی از اشیا میتوانند ساختار بالایی داشته باشند. با این حال، کل مجموعه اشیا ممکن در یک چهارچوب ساختاریافته از پیش تعریف شده قرار نمی گیرد. اکثر DBMS های ساخته شده اکنون از داده های بدون ساختار به روش های مختلف پشتیبانی می کنند و DBMS های اختصاصی جدید در حال ظهور هستند.
سیستم مدیریت پایگاه داده

Connolly و Begg سیستم مدیریت پایگاه داده DBMS را به عنوان «سیستم نرم افزاری که کاربران را قادر می سازد تا دسترسی به پایگاه داده را تعریف، ایجاد، نگهداری و کنترل کنند» تعریف می کنند. نمونه هایی از DBMS ها عبارتند ازMySQL ،PostgreSQL Microsoft SQL Server ،Oracle Database و Microsoft Access.
گاهی اوقات مخفف DBMS برای نشان دادن مدل پایگاه داده پایه ای، با RDBMS برای رابطه ای، OODBMS برای شی (گرا) و ORDBMS برای مدل شی رابطه ای گسترش می یابد. سایر برنامه های افزودنی می توانند مشخصه های دیگری مانند DDBMS برای سیستم های مدیریت پایگاه داده توزیع شده را نشان دهند.
عملکرد ارائه شده توسط یک DBMS می تواند بسیار متفاوت باشد. عملکرد اصلی ذخیره سازی، بازیابی و به روز رسانی داده ها است. Codd توابع و خدمات زیر را پیشنهاد کرد که یک DBMS باید داشته باشد:
- ذخیره سازی داده ها، بازیابی و به روز رسانی
- کاتالوگ در دسترس کاربر که فراداده را توصیف می کند
- پشتیبانی از تراکنش ها و همزمانی
- امکانات بازیابی پایگاه داده در صورت آسیب دیدن آن
- پشتیبانی از مجوز دسترسی و به روز رسانی داده ها
- دسترسی به پشتیبانی از مکان های راه دور
- اعمال محدودیت ها برای اطمینان از این که داده ها در پایگاه داده از قوانین خاصی پیروی می کنند
هم چنین به طور کلی انتظار می رود که DBMS مجموعه ای از ابزارها را برای اهدافی که ممکن است برای مدیریت موثر پایگاه داده ضروری باشد، از جمله ابزارهای import، export، نظارت، تجزیه و تجزیه و تحلیل ارائه دهد. بخش اصلی DBMS در تعامل بین پایگاه داده و رابط برنامه گاهی اوقات به عنوان موتور پایگاه داده شناخته می شود.
اغلب DBMS ها دارای پارامترهای پیکربندی هستند که می توانند به صورت ایستا و پویا تنظیم شوند، به عنوان مثال حداکثر مقدار حافظه اصلی روی یک سرور که پایگاه داده می تواند استفاده کند.
DBMS چند کاربره اولیه معمولا فقط به برنامه اجازه میداد در همان رایانه با دسترسی از طریق پایانهها یا نرمافزار شبیهسازی ترمینال ساکن شود. معماری سرویس گیرنده-سرور توسعه ای بود که در آن برنامه بر روی دسکتاپ مشتری و پایگاه داده روی سرور قرار داشت که امکان توزیع پردازش را فراهم می کرد. این به یک معماری چند لایه تبدیل شد که شامل سرورهای برنامه و سرورهای وب با رابط کاربر نهایی از طریق یک مرورگر وب با پایگاه داده فقط به طور مستقیم به لایه مجاور متصل است.
یک DBMS همه منظوره رابط های برنامه نویسی برنامه عمومی API و به صورت اختیاری یک پردازنده برای زبان های پایگاه داده مانند SQL فراهم می کند تا به برنامه ها اجازه نوشتن برای تعامل با پایگاه داده را بدهد. یک DBMS با هدف ویژه ممکن است از یک API خصوصی استفاده کند و به طور ویژه توسط برنامه نویس شاخته شود و به یک برنامه واحد پیوند داده شود. به عنوان مثال، یک سیستم ایمیل که بسیاری از عملکردهای یک DBMS همه منظوره مانند درج پیام، حذف پیام، مدیریت پیوست، ارتباط پیامها با آدرس ایمیل و غیره را انجام میدهد، اما این توابع محدود به مواردی هستند که برای رسیدگی لازم است.
ویژگی های DBMS

ویژگی های DBMS در زیر آمده است:
- گزارش های پایگاه داده – این ویژگی به نگه داشتن تاریخچه ای از توابع اجرا شده کمک می کند.
- بخش گرافیکی برای تولید نمودارها
- بهینه ساز کوئری - بهینه سازی کوئری را در هر کوئری انجام می دهد تا یک کوئری کارآمد را انتخاب کند تا برای محاسبه نتیجه کوئری اجرا شود.
- ابزارها برای طراحی پایگاه داده، برنامه نویسی برنامه، نگهداری برنامه کاربردی، تجزیه و تحلیل و نظارت بر عملکرد پایگاه داده، نظارت بر پیکربندی پایگاه داده، پیکربندی سخت افزار DBMS یک DBMS و پایگاه داده مرتبط ممکن است شامل رایانه ها، شبکه ها و واحدهای ذخیره سازی شود) و نقشه برداری پایگاه داده مرتبط (به ویژه برای یک DBMS توزیع شده)، تخصیص فضای ذخیره سازی و نظارت بر طرح بندی پایگاه داده، مهاجرت ذخیره سازی و غیره.
برنامه کاربردی (Application)
تعامل خارجی با پایگاه داده از طریق یک برنامه کاربردی خواهد بود که با DBMS ارتباط برقرار می کند. این می تواند از یک ابزار پایگاه داده که به کاربران اجازه می دهد کوئری های SQL را به صورت متنی یا گرافیکی اجرا کنند تا وب سایتی که از پایگاه داده برای ذخیره و جستجوی اطلاعات استفاده می کند، متغیر باشد.
رابط برنامه کاربردی
یک برنامه نویس از طریق یک رابط برنامه کاربردی API یا از طریق یک زبان پایگاه داده، تعاملات را با پایگاه داده برقرار می کند. API یا زبان خاص انتخاب شده باید توسط DBMS پشتیبانی شود، این امکان به طور غیرمستقیم از طریق یک پیش پردازنده یا یک API پل ارتباطی وجود دارد. هدف برخی از API این است که از پایگاه داده مستقل باشند، ODBC یک نمونه معمول شناخته شده است. سایر APIهای رایج عبارتند از JDBC و ADO.NET.
زبان های پایگاه داده
زبانهای پایگاه داده، زبانهایی با هدف خاص هستند که یک یا چند مورد از وظایف زیر را که گاهی اوقات با عنوان زیرزبانها شناخته میشوند، امکان پذیر میسازند:
- زبان کنترل داده ها DCL - دسترسی به داده ها را کنترل می کند.
- زبان تعریف داده DDL - انواع داده ها مانند ایجاد، تغییر یا حذف جداول و روابط بین آن ها را تعریف می کند.
- زبان دستکاری داده ها DML - کارهایی مانند درج، به روز رسانی یا حذف داده ها را انجام می دهد.
- زبان پرس و جوی داده ها DQL - امکان جستجوی اطلاعات را فراهم می کند.
زبان های پایگاه داده مختص یک مدل داده خاص هستند. نمونه های قابل توجه عبارتند از:
- SQL نقش های تعریف داده، دستکاری داده ها و کوئری را در یک زبان واحد ترکیب می کند. این یکی از اولین زبانهای تجاری برای مدل رابطهای بود، اگرچه از برخی جهات از مدل رابطهای که توسط Codd توضیح داده شده فاصله میگیرد (برای مثال، سطر ها و ستونهای یک جدول را میتوان مرتب کرد). SQL در سال 1986 به استاندارد موسسه استانداردهای ملی آمریکا ANSI و در سال 1987 برای سازمان بین المللی استاندارد ISO تبدیل شد. استانداردها از آن زمان به طور مرتب بهبود یافته اند و با درجات مختلف انطباق توسط همه تجاری اصلی پشتیبانی می شوند.
- OQL یک استاندارد زبان مدل شی از Object Data Management Group است. این بر طراحی برخی از زبانهای جستجوی جدیدتر مانند JDOQL و EJB QL تاثیر گذاشته است.
- XQuery یک زبان پرس و جوی XML استاندارد است که توسط سیستم های پایگاه داده XML مانند MarkLogic و eXist، توسط پایگاه های داده رابطه ای با قابلیت XML مانند Oracle و DB2 و همچنین توسط پردازنده های XML درون حافظه مانند Saxon پیاده سازی شده است.
- SQL/XML XQuery را با SQL ترکیب می کند.
زبان پایگاه داده ممکن است دارای ویژگی هایی مانند زیر باشد:
- پیکربندی و مدیریت موتور ذخیره سازی DBMS
- محاسبات برای تغییر نتایج کوئری، مانند شمارش، جمع بندی، میانگین گیری، مرتب سازی، گروه بندی و ارجاع متقابل
- اعمال محدودیت (مثلا در پایگاه داده خودرو، فقط یک نوع موتور در هر خودرو مجاز است)
- نسخه رابط برنامه نویسی برنامه از زبان کوئری، برای راحتی برنامه نویس
ذخیره سازی پایگاه داده
ذخیره سازی پایگاه داده یک نگهدارنده است که تحقق فیزیکی یک پایگاه داده را ممکن می سازد. این نگهدارنده شامل سطح داخلی (فیزیکی) در معماری پایگاه داده است. هم چنین شامل تمام اطلاعات مورد نیاز (به عنوان مثال، فراداده، "داده های مربوط به داده ها" و ساختارهای داده داخلی) برای بازسازی سطح مفهومی و سطح خارجی از سطح داخلی، در صورت نیاز است. پایگاه های داده به عنوان اشیا دیجیتال شامل سه لایه اطلاعات هستند که باید ذخیره شوند: داده ها، ساختار و معناشناسی. ذخیره سازی مناسب هر سه لایه برای حفظ و ماندگاری آینده پایگاه داده مورد نیاز است. قرار دادن داده ها در ذخیره سازی دائمی به طور کلی بر عهده موتور پایگاه داده با نام "موتور ذخیره سازی" است.
اگرچه معمولا توسط یک DBMS از طریق سیستم عامل زیربنایی (و اغلب با استفاده از سیستم فایل سیستم عامل به عنوان واسطه برای چیدمان ذخیره سازی) قابل دسترسی است، ویژگی های ذخیره سازی و تنظیمات پیکربندی برای عملکرد کارآمد DBMS بسیار مهم هستند، و بنابراین از نزدیک توسط DBMS نگهداری می شوند. مدیران پایگاه داده یک DBMS، در حین کارکرد، همیشه پایگاه داده خود را در چندین نوع ذخیره سازی (مانند حافظه و حافظه خارجی) قرار می دهد. داده های پایگاه داده و اطلاعات مورد نیاز اضافی، احتمالا در مقادیر بسیار زیاد، در بیت ها کدگذاری می شوند.
دادهها معمولا در ساختارهای ذخیرهسازی قرار میگیرند که کاملا متفاوت از شکل ظاهری دادهها در سطوح مفهومی و خارجی به نظر میرسند، اما به روشهایی که سعی در بهینهسازی (بهترین ممکن) بازسازی این سطوح در صورت نیاز توسط کاربران و برنامهها دارند.برخی از DBMS ها از تعیین رمزگذاری اندیس برای ذخیره داده ها پشتیبانی می کنند، بنابراین می توان از چندین رمزگذاری در یک پایگاه داده استفاده کرد.
ساختارهای مختلف ذخیره سازی پایگاه داده سطح پایین توسط موتور ذخیره سازی برای سریال سازی مدل داده استفاده می شود تا بتوان آن را در رسانه انتخابی نوشت. ممکن است از تکنیک هایی مانند اندیس سازی برای بهبود عملکرد استفاده شود. ذخیره سازی معمولی ردیف گرا است، اما پایگاه داده ستون محور و همبستگی نیز وجود دارد.
همانند سازی
گاهی اوقات یک پایگاه داده از افزونگی ذخیره سازی توسط تکثیر اشیا پایگاه داده (با یک یا چند نسخه) استفاده می کند تا در دسترس بودن داده ها را افزایش دهد (هم برای بهبود عملکرد دسترسی های چند کاربر نهایی همزمان به یک شی پایگاه داده یکسان و هم برای ایجاد انعطاف پذیری در صورت شکست جزئی پایگاه داده توزیع شده). بهروزرسانیهای یک شی تکراری باید در سراسر کپیهای شی همگام شوند. در بسیاری از موارد، کل پایگاه داده همانند سازی می شود.
امنیت پایگاه داده
امنیت پایگاه داده با تمام جنبه های مختلف حفاظت از محتوای پایگاه داده، صاحبان آن و کاربران آن سروکار دارد. از حفاظت از استفاده های غیرمجاز عمدی پایگاه داده تا دسترسی های غیرعمدی به پایگاه داده توسط نهادهای غیرمجاز (به عنوان مثال، یک شخص یا یک برنامه رایانه ای) متغیر است.
کنترل دسترسی به پایگاه داده با کنترل اینکه چه کسی (یک شخص یا یک برنامه کامپیوتری خاص) مجاز است به چه اطلاعاتی در پایگاه داده دسترسی داشته باشد، سروکار دارد. اطلاعات ممکن است شامل اشیا پایگاه داده خاص (مانند انواع رکورد، رکوردهای خاص، ساختارهای داده)، محاسبات خاص بر روی اشیا خاص (مانند انواع پرس و جو یا پرس و جوهای خاص) یا استفاده از مسیرهای دسترسی خاص به اولی (مثلا استفاده از اندیس های خاص) باشد. یا سایر ساختارهای داده برای دسترسی به اطلاعات). کنترلهای دسترسی به پایگاه داده توسط پرسنل مجاز ویژه (توسط مالک پایگاه داده) تنظیم میشوند که از رابطهای امنیتی حفاظت شده اختصاصی DBMS استفاده میکنند.
امنیت داده ها از مشاهده یا به روز رسانی پایگاه داده توسط کاربران غیرمجاز جلوگیری می کند. با استفاده از گذرواژه ها، کاربران اجازه دسترسی به کل پایگاه داده یا زیرمجموعه های آن به نام subschemas را دارند. به عنوان مثال، یک پایگاه داده کارمند میتواند حاوی تمام دادههای مربوط به یک کارمند باشد، اما یک گروه از کاربران ممکن است مجاز به مشاهده فقط دادههای حقوق و دستمزد باشند، در حالی که دیگران فقط به سابقه کار و دادههای پزشکی اجازه دسترسی دارند. اگر DBMS راهی برای ورود و به روز رسانی تعاملی پایگاه داده و همچنین بازجویی از آن فراهم کند، این قابلیت امکان مدیریت پایگاه داده های شخصی را فراهم می کند.
تراکنش و همزمانی
از تراکنش های پایگاه داده می توان برای معرفی سطحی از تحمل خطا و یکپارچگی داده ها پس از بازیابی استفاده کرد. تراکنش پایگاه داده واحدی از کار است که معمولا تعدادی عملیات را روی یک پایگاه داده کپسوله می کند. هر تراکنش دارای مرزهای مشخصی است که از نظر اجرای برنامه/کد در آن تراکنش گنجانده شده است (که توسط برنامه نویس تراکنش از طریق دستورات تراکنش خاص تعیین می شود). ACID برخی از ویژگی های ایده آل یک تراکنش پایگاه داده را توصیف می کند و سرنام موارد زیر است:
- atomicity (اتمی بودن)
- consistency (سازگاری)
- isolation (جداسازی)
- durability (دوام)
مهاجرت
پایگاه داده ای که با یک DBMS ساخته شده است قابل انتقال به یک DBMS دیگر نیست (یعنی DBMS دیگر نمی تواند آن را اجرا کند). با این حال، در برخی شرایط، انتقال پایگاه داده از یک DBMS به DBMS دیگر مطلوب است. دلایل در درجه اول اقتصادی هستند (DBMS های مختلف ممکن است هزینه های کل مالکیت یا TCO های متفاوتی داشته باشند)، عملکردی و عملیاتی هستند (DBMS های مختلف ممکن است قابلیت های متفاوتی داشته باشند).
مهاجرت شامل تبدیل پایگاه داده از یک نوع DBMS به نوع دیگر است. تبدیل باید (در صورت امکان) برنامه مربوط به پایگاه داده (یعنی همه برنامه های کاربردی مرتبط) را دست نخورده نگه دارد. بنابراین، سطوح مفهومی و معماری خارجی پایگاه داده باید در تحول حفظ شود. ممکن است مطلوب باشد که برخی از جنبه های سطح داخلی معماری نیز حفظ شود. انتقال پایگاه داده پیچیده یا بزرگ ممکن است به خودی خود یک پروژه پیچیده و پرهزینه (یک بار مصرف) باشد که باید در تصمیم گیری برای مهاجرت لحاظ شود.
ساخت، نگهداری و تنظیم پایگاه داده
پس از طراحی پایگاه داده برای یک برنامه، مرحله بعدی ساخت پایگاه داده است. به طور معمول، یک DBMS همه منظوره مناسب را می توان برای استفاده برای این منظور انتخاب کرد. یک DBMS رابط های کاربری مورد نیاز را برای استفاده توسط مدیران پایگاه داده برای تعریف ساختارهای داده برنامه مورد نیاز در مدل داده مربوطه DBMS فراهم می کند. سایر رابط های کاربری برای انتخاب پارامترهای DBMS مورد نیاز (مانند مربوط به امنیت، پارامترهای تخصیص فضای ذخیره سازی و غیره) استفاده می شود.
هنگامی که پایگاه داده آماده است، معمولا با داده های اولیه برنامه پر می شود.
پس از ایجاد پایگاه داده، مقداردهی اولیه و پر شدن آن، باید از آن نگهداری شود. پارامترهای مختلف پایگاه داده ممکن است نیاز به تغییر داشته باشند و پایگاه داده ممکن است نیاز به تنظیم برای عملکرد بهتر داشته باشد. ساختمان داده های برنامه ممکن است تغییر یا اضافه شود، برنامه های کاربردی مرتبط جدید ممکن است برای افزودن به عملکرد برنامه نوشته شوند و غیره.
پشتیبان گیری و بازیابی
گاهی اوقات میخواهیم پایگاه داده را به حالت قبلی برگردانیم (به دلایل بسیاری، به عنوان مثال، مواردی که پایگاه داده به دلیل یک خطای نرمافزاری خراب شده است، یا اگر با دادههای اشتباه بهروزرسانی شده باشد). برای دستیابی به این هدف، یک عملیات پشتیبان گیری گه گاه یا به طور مداوم انجام می شود، جایی که هر وضعیت پایگاه داده مورد نظر (یعنی مقادیر داده های آن و جاسازی آن ها در ساختارهای داده پایگاه داده) در فایل های پشتیبان اختصاصی نگهداری می شود (تکنیک های زیادی برای انجام موثر این کار وجود دارد). هنگامی که مدیر پایگاه داده تصمیم می گیرد که پایگاه داده را به این حالت بازگرداند (به عنوان مثال، با تعیین این وضعیت در یک نقطه زمانی دلخواه در زمانی که پایگاه داده در این حالت قرار داشت)، از این فایل ها برای بازیابی آن حالت استفاده می شود.
طراحی و مدل سازی پایگاه داده
اولین وظیفه یک طراح پایگاه داده تولید یک مدل داده مفهومی است که ساختار اطلاعاتی را که قرار است در پایگاه داده نگهداری شود نشان دهد. یکی از روش های انجام این کار، استفاده از یک مدل رابطه موجودیت ها است. یکی دیگر از رویکردهای محبوب، زبان مدلسازی یکپارچه است. یک مدل داده موفق، وضعیت احتمالی دنیایی را که در حال مدلسازی است، به دقت بازتاب میکند.برای مثال، اگر افراد بتوانند بیش از یک شماره تلفن داشته باشند، اجازه میدهد تا این اطلاعات ثبت شود. طراحی یک مدل داده مفهومی خوب نیاز به درک خوبی از حوزه کاربرد دارد.
مدل ها
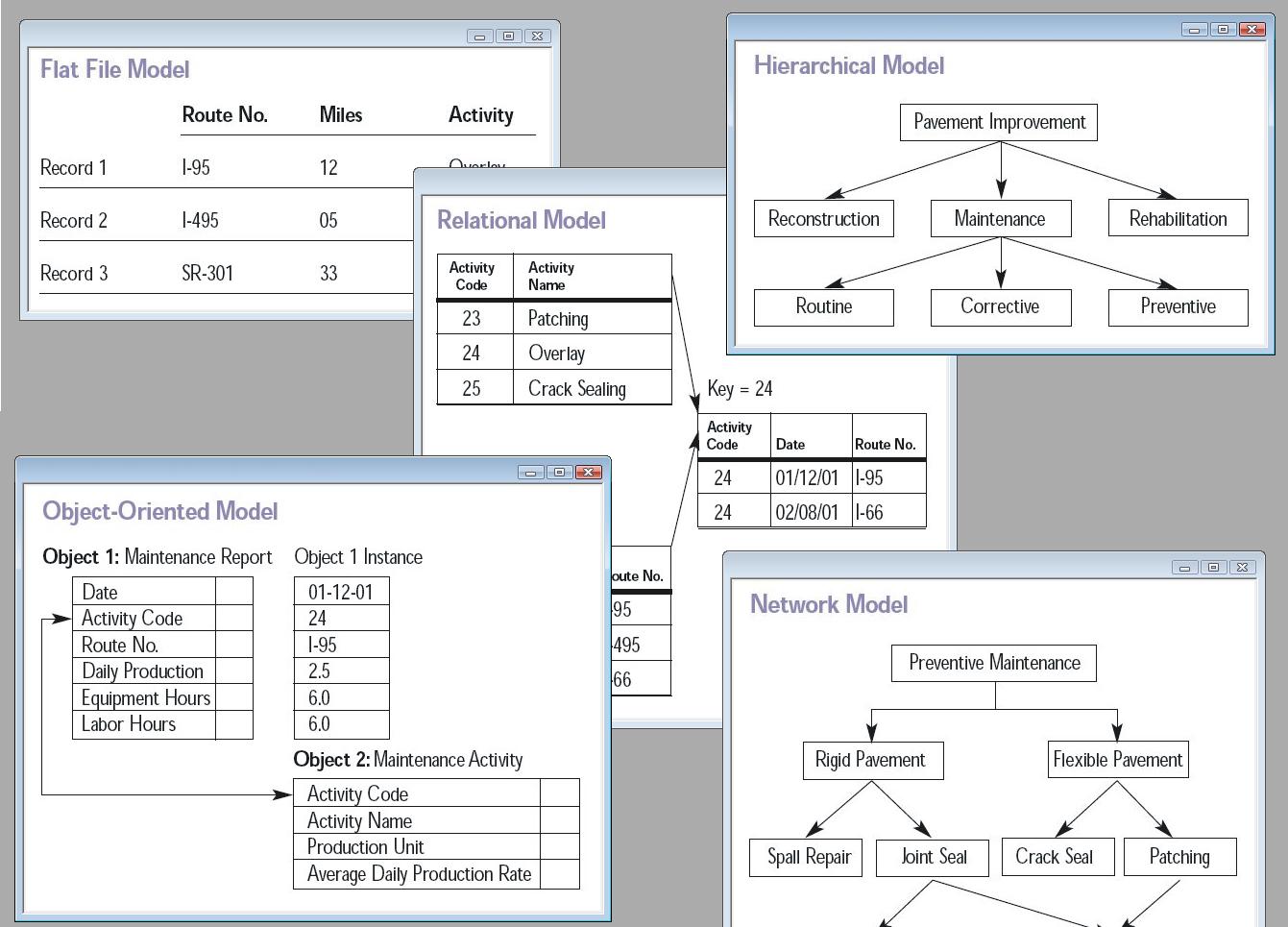
مدل پایگاه داده نوعی مدل داده است که ساختار منطقی یک پایگاه داده را تعیین می کند و اساسا تعیین می کند که به چه روشی داده ها می توانند ذخیره، سازماندهی و دستکاری شوند. محبوب ترین نمونه از مدل پایگاه داده، مدل رابطه ای (یا SQL رابطه ای) است که از یک فرمت مبتنی بر جدول استفاده می کند.
مدل های داده های منطقی رایج برای پایگاه های داده عبارتند از:
- پایگاه داده های ناوبری
- مدل پایگاه داده سلسله مراتبی
- مدل شبکه
- پایگاه داده نمودار
- مدل رابطه ای
- مدل نهاد-رابطه
- مدل روابط موجودیت پیشرفته
- مدل شی
- مدل سند
- مدل نهاد – ویژگی – ارزش
- طرح واره ستاره ای
یک پایگاه داده شی رابطه ای دو ساختار مرتبط را با هم ترکیب می کند.
مدل های داده های فیزیکی عبارتند از:
- اندیس وارونه
- Flat File
مدل های دیگر عبارتند از:
- مدل چند بعدی
- مدل آرایه
- مدل چند ارزشی
مدل های تخصصی برای انواع خاصی از داده ها بهینه شده اند:
- پایگاه داده XML
- مدل معنایی
- store محتوا
- store رویداد
- مدل سری زمانی
view های بیرونی، مفهومی و درونی
یک سیستم مدیریت پایگاه داده سه نما یا view از داده های پایگاه داده را ارائه می دهد:
- سطح خارجی مشخص می کند که هر گروه از کاربران نهایی چگونه سازماندهی داده ها را در پایگاه داده می بینند. یک پایگاه داده واحد می تواند هر تعداد نما در سطح خارجی داشته باشد.
- سطح مفهومی نمای های مختلف خارجی را در یک نمای سراسری سازگار یکی می کند. این ترکیب همه نماهای خارجی را فراهم می کند.
- سطح داخلی (یا سطح فیزیکی) سازماندهی داخلی داده ها در داخل یک DBMS است. به هزینه، عملکرد، مقیاس پذیری و سایر موارد عملیاتی مربوط می شود.
در حالی که فقط یک نما مفهومی (یا منطقی) و فیزیکی (یا داخلی) از داده ها وجود دارد، می تواند تعداد زیادی نما خارجی متفاوت وجود داشته باشد.
معماری پایگاه داده سه سطحی به مفهوم استقلال داده مربوط می شود که یکی از اصلی ترین ویژگی های مدل رابطه ای بود. ایده این است که تغییرات ایجاد شده در یک سطح معین بر نمای سطح بالاتر تاثیر نمی گذارد. به عنوان مثال، تغییرات در سطح داخلی برنامه های کاربردی نوشته شده با استفاده از رابط های سطح مفهومی را تحت تاثیر قرار نمی دهد، که تاثیر ایجاد تغییرات فیزیکی برای بهبود عملکرد را کاهش می دهد.
منبع: ویکیپدیا








در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.