استخراج اطلاعات از سایت با پایتون
Web Scraping with Python

Beautiful Soup: ساخت یک وب اسکریپر (Web Scraper) با پایتون
حجم باورنکردنی دادهها در اینترنت یک منبع بسیار بزرگ و پر بار برای هر زمینه تحقیقاتی به حساب میآید. برای استخراج اطلاعات از وب سایت با پایتون، باید در وب اسکرپرپینگ (Web Scraping) ماهر شوید. کتابخانه های requests و Beautiful Soup از پایتون ابزارهای قدرتمندی برای این کار هستند. اگر دوست دارید با مثال های عملی یاد بگیرید و درک اولیه ای از Python و HTML داشته باشید، این آموزش برای شما مناسب است.
در این آموزش، شما یاد خواهید گرفت که چگونه:
- داده های رمزگذاری شده در URL ها را رمزگشایی کنید
- از requests و Beautiful Soup برای Scrape کردن و تجزیه داده های وب استفاده کنید
- از ابتدا تا انتها با وب اسکرپینگ یا استخراج اطلاعات از وب سایت با پایتون آشنا شوید
- اسکریپتی بسازید که پیشنهادهای شغلی را از وب واکشی کند و اطلاعات مرتبط را در کنسول شما نمایش دهد و در نهایت بتوانید استخراج اطلاعات از یک وب سایت را با پایتون به راحتی انجام دهید.
کار بر روی این پروژه به شما دانش لازم و ابزارهایی را می دهد که برای اسکرپ کردن هر وب سایت ایستا در وب نیاز دارید. با کلیک بر روی لینک زیر می توانید کد اصلی پروژه را دانلود کنید:
دریافت کد: برای دانلود کد نمونه و کد های دیگر در این آموزش اینجا را کلیک کنید.
بیایید شروع کنیم!
وب اسکرپینگ (Web Scraping) چیست؟
وب اسکرپینگ یا (استخراج اطلاعات از وب سایت ها) فرآیند جمع آوری اطلاعات از اینترنت است. حتی کپی و پیست کردن متن آهنگ مورد علاقه شما نوعی از وب اسکرپینگ است! با این حال، عبارت "web scraping" معمولا به فرآیندی اشاره دارد که شامل اتوماسیون یا خودکارسازی است. برخی از وبسایتها از جمعآوری خودکار اطلاعات استقبال نمیکنند، ولی برخی دیگر اصلا اهمیتی به این موضوع نمیدهند.
اگر برای اهداف آموزشی و با رعایت احترام و حقوق مالک وب سایت، صفحه ای را اسکرپ میکنید، بعید است که مشکلی پیش بیاید. با این حال، بهتر است قبل از نوشتن یک پروژه در مقیاس بزرگ، خودتان تحقیق کنید و مطمئن شوید که هیچ یک از شرایط سایت را نقض نمی کنید.
دلایل استفاده از وب اسکرپینگ (استخراج اطلاعات) چیست؟
فرض کنید یک موج سوار هستید، ، و چه به صورت آنلاین و چه به صورت حضوری دنبال شغل هستید. شما با طرز فکر یک موج سوار، منتظر فرصت عالی هستید تا راه حرفه ای خود را پیدا کنید!
یک سایت کار یابی وجود دارد که انواع مشاغل مورد نظر شما را ارائه می دهد. متاسفانه، یک موقعیت شغلی جدید فقط یک بار در ماه برای شما پیدا می شود و سایت سرویس اعلان ایمیل را هم ارائه نمی دهد. شما هر روز مجبورید سایت را برای پیدا کردن شغل بررسی کنید، که به نظر سرگرم کننده و جالب نیست.
خوشبختانه، دنیا راه های دیگری برای تحقق یافتن طرز فکر یک موج سوار ارائه می دهد! به جای اینکه هر روز به سایت کاریابی نگاه کنید، می توانید از پایتون برای کمک به خودکارسازی قسمت های تکراری جستجوی مشاغل استفاده کنید. حذف خودکار محتوی وب می تواند راه حلی برای تسریع روند جمع آوری داده ها باشد. شما کد را یک بار می نویسید و با این کار اطلاعات مورد نظر خود را بارها از صفحات مختلف دریافت می کنید.
در مقابل، زمانی که سعی می کنید اطلاعات مورد نظر خود را خودتان دریافت کنید، ممکن است زمان زیادی را صرف کلیک کردن، پیمایش و جستجو کنید، به خصوص اگر به حجم زیادی از داده ها از وب سایت هایی نیاز دارید که به طور منظم با محتوی جدید به روز می شوند. استخراج اطلاعات از وب سایت به صورت دستی می تواند زمان بسیار زیاد و تکرار پذیری را بالا ببرد.
اطلاعات زیادی در وب وجود دارد و اطلاعات جدید به طور مداوم اضافه می شوند. احتمالا به برخی از این داده ها علاقه مند خواهید شد، و بسیاری از آنها فقط وجود خواهند داشت. خواه واقعا در جستجوی کار هستید یا می خواهید تمام اشعار هنرمند مورد علاقه خود را دانلود کنید، استخراج اطلاعات خودکار وب می تواند به شما در دستیابی به اهدافتان کمک کند.
چالش های اسکرپینگ وب (استخراج اطلاعات)
وب به طور طبیعی با استفاده از منابع بسیاری رشد کرده است. به عبارت دیگر، وب یک بازار شام است! به همین دلیل، هنگام استخراج اطلاعات از وب سایت ها با چالش هایی مواجه خواهید شد:
- تنوع: هر وب سایتی با دیگری متفاوت است. درست است که با ساختارهای کلی مواجه خواهید شد که مداوم خود را تکرار می کنند، ولی با این وجود هر وب سایت یکتا است و اگر می خواهید اطلاعات مرتبط با آن را استخراج کنید، نیاز به تصمیم گیری شخصی دارد.
- دوام: وب سایت ها دائما تغییر می کنند. فرض کنید که یک وب اسکرپر جدید ساخته اید که به طور خودکار آنچه را که می خواهید از منبع مورد علاقه شما انتخاب می کند. اولین باری که اسکریپت خود را اجرا می کنید، بدون نقص کار می کند. اما وقتی همان اسکریپت را فقط مدت کوتاهی بعد اجرا میکنید، با نتیجهای کسل کننده مواجه میشوید!
در نتیجه اسکریپت ها ناکارآمد خواهند شد، چون بسیاری از وب سایت ها در حال توسعه بوده و مدام تغییر میکنند. هنگامی که ساختار سایت تغییر کرد، اسکرپر شما ممکن است نتواند نقشه سایت را به درستی پیمایش کند یا اطلاعات مربوطه را پیدا کند. خبر خوب این است که بسیاری از تغییرات در وبسایتها کوچک و تدریجی هستند، بنابراین میتوانید اسکرپر خود را با حداقل زمان ممکن بهروزرسانی کنید.
با این حال، به خاطر داشته باشید که از آنجایی که اینترنت پویا است، اسکرپرهایی که میسازید احتمالا نیاز به نگهداری مداوم دارند. میتوانید یکپارچهسازی مداوم را برای اجرای دورهای تستهای اسکرپینگ بسازید تا مطمئن شوید که اسکریپت اصلی شما بدون اطلاع شما خراب نمیشود.
جایگزینی برای وب اسکرپینگ: API ها
برخی از تولیدکنندگان وب سایت ها، رابط های برنامه نویسی کاربردی (API) را ارائه می دهند که به شما امکان می دهد به داده های آنها به روشی از پیش تعریف شده دسترسی داشته باشید. با API ها، می توانید از تجزیه HTML اجتناب کنید. در عوض، می توانید به طور مستقیم با استفاده از فرمت هایی مانند JSON و XML به داده ها دسترسی داشته باشید. HTML در درجه اول راهی برای ارائه محتوا به کاربران به صورت بصری است.
هنگامی که از یک API استفاده می کنید، کار شما به طور کلی پایدارتر از جمع آوری داده ها از طریق استخراج اطلاعات از وب سایت با پایتون است. به این دلیل که توسعه دهندگان API هایی را ایجاد می کنند تا توسط برنامه ها استفاده شود.
فرانت اند یک سایت ممکن است اغلب تغییر کند، اما چنین تغییری در طراحی وب سایت بر ساختار API آن تاثیر نمی گذارد. ساختار یک API معمولا ثابت تر است، به این معنی که منبع قابل اعتمادتری از دادههای سایت است.
با این حال، API ها نیز می توانند تغییر کنند. چالشهای متنوع بودن و دوام برای APIها نیز مانند وبسایتها اعمال میشود. علاوه بر این، اگر مستندات ارائه شده ضعیف باشند، بررسی ساختار یک API توسط خودتان بسیار دشوارتر است.
رویکرد و ابزارهایی که برای جمعآوری اطلاعات با استفاده از APIها نیاز دارید، خارج از محدوده این آموزش هستند. برای کسب اطلاعات بیشتر در مورد آن، یکپارچه سازی API در پایتون را بررسی کنید.
استخراج اطلاعات سایت کاریابی فیک که با پایتون ساخته شده است
در این آموزش، یک وب اسکرپر میسازید که فهرستهای شغلی توسعهدهنده نرمافزار پایتون را از سایت کاریابی فیک ساخته شده با پایتون واکشی میکند. این سایت یک سایت نمونه با آگهیهای کاریابی فیک است که میتوانید آزادانه از آن استفاده کنید. وب اسکرپر شما HTML سایت را تجزیه می کند تا اطلاعات مربوطه را انتخاب کند و محتوا را برای کلمات خاص فیلتر میکند.
شما می توانید هر سایتی را در اینترنت، اسکرپ کنید، اما سختی انجام این کار به سایت بستگی دارد. این آموزش مقدمهای بر اسکرپینگ وب (استخراج اطلاعات) به شما ارائه میدهد تا به شما در درک فرآیند کلی کمک کند. سپس، می توانید همین فرآیند را برای هر وب سایتی که می خواهید اسکرپ کنید، اعمال کنید.
در طول آموزش، با چند تمرین نیز روبهرو خواهید شد.
مرحله 1: بررسی منبع داده
قبل از نوشتن هر نوع کد پایتون، باید وب سایتی را که می خواهید اسکرپ کنید، بشناسید. این باید اولین قدم شما برای هر پروژه وب اسکرپینگ باشد. برای استخراج اطلاعات باید ساختار سایت را درک کنید. با باز کردن سایت با مرورگر مورد علاقه خود که می خواهید اسکرپ کنید شروع کنید.
بررسی سایت
برای استخراج اطلاعات وب سایت با پایتون ابتدا وارد این سایت شوید و مانند هر کاربر معمولی با آن رفتار کنید. به عنوان مثال، می توانید در صفحه اصلی وب سایت جستجو کنید:
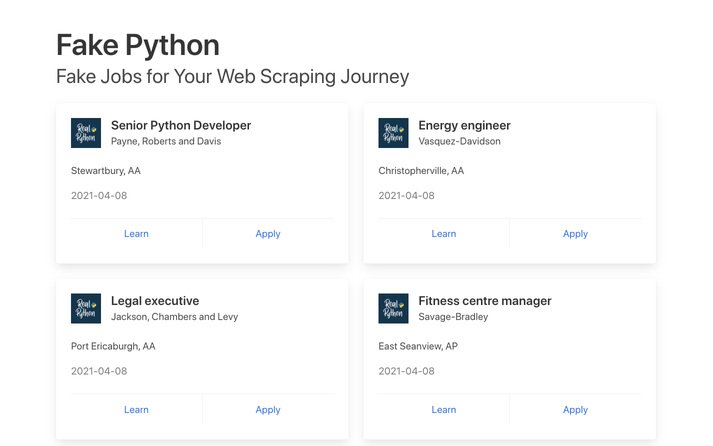
شما می توانید خیلی از آگهی های شغلی را در قالب کارت مشاهده کنید و هر کدام دارای دو دکمه هستند. اگر روی Apply کلیک کنید، صفحه جدیدی خواهید دید که حاوی توضیحات دقیق تری از شغل انتخاب شده است. همچنین ممکن است متوجه شوید که URL در نوار آدرس مرورگر شما هنگام کار کردن با سایت تغییر می کند.
رمزگشایی برای استخراج اطلاعات موجود در URL ها
یک برنامه نویس می تواند اطلاعات زیادی را در یک URL رمزگذاری کند. اگر از ابتدا با نحوه کار URL ها و ساختار آن ها آشنا شوید، سفر اسکراپ کردن سایت شما بسیار آسان تر خواهد بود. برای مثال، ممکن است با یک صفحه جزئیات روبهرو شوید که دارای URL زیر باشد:
https://realpython.github.io/fake-jobs/jobs/senior-python-developer-0.html
شما می توانید URL بالا را به دو بخش اصلی تجزیه کنید:
- base URL یا URL پایه نشان دهنده مسیر عملکرد جستجوی وب سایت است. در مثال بالا، URL پایه https://realpython.github.io/fake-jobs/ است.
- مکانی خاص در سایت که با .html پایان کرده است، مسیر منبع منحصر به فرد مربوط به شرح شغل است.
هر شغلی که در این وب سایت باشد از همین URL base استفاده می کند. با این حال، مکان منابع ویژه با توجه به اینکه چه موقعیت شغلی خاصی را مشاهده می کنید، متفاوت خواهد بود.
URLها می توانند اطلاعات بیشتری را علاوه بر مکان یک فایل در خود نگه دارند. برخی از وب سایت ها از پارامترهای کوئری برای رمزگذاری مقادیری که هنگام انجام جستجو ارسال می کنید استفاده می کنند. می توانید آنها را به عنوان رشته های کوئری در نظر بگیرید که برای بازیابی رکوردهای خاص به پایگاه داده ارسال می کنید.
پارامترهای جستجو را در انتهای URL پیدا خواهید کرد. به عنوان مثال، اگر به Indeed بروید و با استفاده از نوار جستجو "software developer" در "Australia" را جستجو کنید، خواهید دید که URL تغییر می کند تا این مقادیر را به عنوان پارامترهای جستجو در نظر بگیرد:
https://au.indeed.com/jobs?q=software+developer&l=Australia
پارامترهای کوئری در این URL عبارتند از ?q=software+developer&l=Australia. پارامترهای کوئری از سه بخش تشکیل شده اند:
- شروع: ابتدای پارامترهای کوئری با علامت سوال (؟) مشخص می شود.
- اطلاعات: قطعه اطلاعاتی که یک پارامتر کوئری را تشکیل می دهند به صورت جفت کلید-مقدار کدگذاری می شوند، جایی که کلیدها و مقادیر مرتبط با علامت تساوی (کلید=مقدار) به یکدیگر متصل می شوند.
- جداکننده (separator): هر URL می تواند چندین پارامتر کوئری داشته باشد که با علامت (&) از هم جدا شده اند.
با استفاده از این اطلاعات، می توانید پارامترهای کوئری URL را به دو جفت کلید-مقدار جدا کنید:
- q=software+developer نوع کار را انتخاب می کند.
- l=Australia محل کار را انتخاب می کند.
سعی کنید پارامترهای کوئری یا جستجو را تغییر دهید و مشاهده کنید که چگونه بر URL شما تاثیر می گذارد. ادامه دهید و مقادیر جدید را در نوار جستجوی بالا وارد کنید:
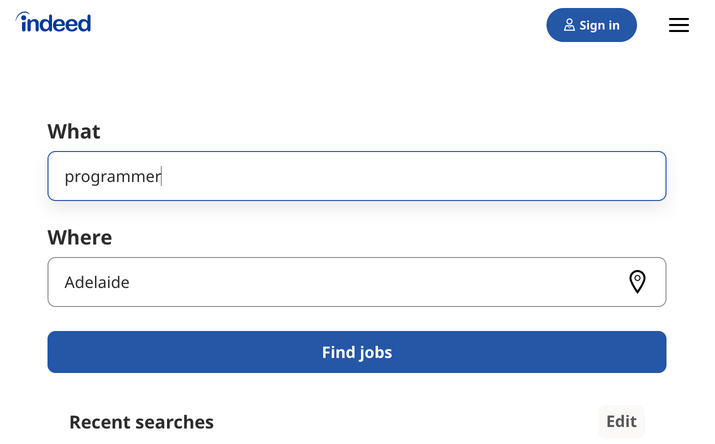
این مقادیر را تغییر دهید تا تغییرات URL را مشاهده کنید.
https://au.indeed.com/jobs?q=developer&l=perth
اگر مقادیر را در کادر جستجوی وب سایت تغییر دهید و سپس ارسال کنید، آنگاه به طور مستقیم در پارامترهای جستجوی URL منعکس می شود و بالعکس. اگر یکی از آنها را تغییر دهید، نتایج متفاوتی را در وب سایت خواهید دید.
همانطور که میبینید، کاوش در URL های یک سایت می تواند به شما بینشی در مورد نحوه بازیابی داده ها از سرور سایت بدهد.
به Fake Python Jobs برگردید و به کاوش در آن ادامه دهید. این سایت یک وب سایت کاملا ایستا است که از پایگاه داده استفاده نمی کند، به همین دلیل است که در این آموزش نیازی به کار با پارامترهای کوئری ندارید.
بررسی سایت با استفاده از Developer Tools
در مرحله بعد، باید درباره سینتکس ساختمان داده ها برای نمایش بیشتر بدانید. برای انتخاب پاسخ HTML که در یکی از مراحل آتی جمع آوری می کنید، باید ساختار صفحه را درک کنید.
Developer Tools می توانند به شما در درک ساختار یک وب سایت کمک کنند. همه مرورگرهای مدرن با Developer Tools از پیش نصب شده عرضه می شوند. در این بخش نحوه کار با ابزارهای توسعه دهنده در کروم را خواهید دید. این کار بسیار شبیه به سایر مرورگرهای مدرن خواهد بود.
در Chrome در macOS، میتوانید با انتخاب View → Developer → Developer Tools، ابزارهای برنامهنویس را از طریق منو باز کنید. در ویندوز و لینوکس، میتوانید با کلیک کردن روی دکمه منوی سمت راست بالا (⋮) و انتخاب More tools → Developer Tools به آنها دسترسی داشته باشید. همچنین می توانید با کلیک راست بر روی صفحه و انتخاب گزینه Inspect یا استفاده از میانبر صفحه کلید به ابزارهای توسعه دهنده خود دسترسی پیدا کنید:
- Mac: Cmd+Alt+I
- Windows/Linux: Ctrl+Shift+I
ابزارهای توسعهدهنده به شما این امکان را میدهند که به طور تعاملی مدل شی گرای سند (DOM) سایت را برای درک بهتر منبع خود کاوش کنید. برای جستجو در DOM صفحه خود، تب Elements را در ابزارهای توسعه دهنده انتخاب کنید. ساختاری با المنت ها HTML قابل کلیک خواهید دید. می توانید المنت ها را به طور مستقیم در مرورگر خود باز، جمع آوری و حتی ویرایش کنید:
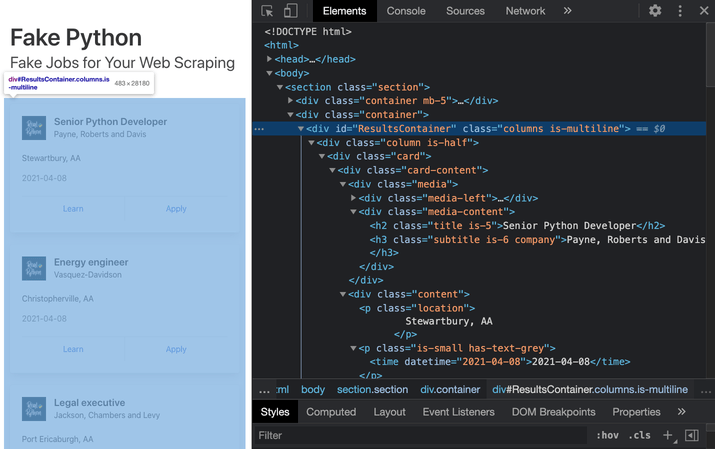
HTML سمت راست نشان دهنده ساختار صفحه ای است که می توانید در سمت چپ ببینید.
می توانید متن نمایش داده شده در مرورگر خود را با ساختار HTML آن صفحه ببینید. وقتی روی المنت های صفحه کلیک راست میکنید، میتوانید Inspect را انتخاب کنید تا به مکان آنها در DOM هدایت شوید. همچنین می توانید موس را روی متن HTML در سمت راست خود نگه دارید و ببینید که المنت های مربوطه در صفحه رنگی می شوند.
کد آن را میتوانید در زیر ببینید:

تمرین و جستجو! هر چه بیشتر با صفحه ای که با آن کار می کنید آشنا شوید، اسکرپ کردن آن آسانتر خواهد بود. با این حال، زیاد در HTML غرق نشوید. شما از قدرت برنامه نویسی استفاده خواهید کرد تا بتوانید اسکرپ کنید و اطلاعات مربوط به خود را انتخاب کنید.
همچنین در صورتیکه با HTML و CSS آشنایی ندارید می تواند دوره آموزش مقدماتی تا پیشرفته HTML و CSS روکسو را ببینید.
مرحله 2: پاک کردن محتوی HTML از یک صفحه
اکنون که ایده ای در مورد آنچه که در آینده قرار است با آن کار کنید دارید، وقت آن است که استفاده از پایتون را شروع کنید. ابتدا، می خواهید کد HTML سایت را در اسکریپت پایتون خود وارد کنید تا بتوانید با آن تعامل داشته باشید. برای این کار، از کتابخانه requests پایتون استفاده خواهیم کرد.
از آنجا برای کار کردن با این مباحث باید به زبان پایتون تسلط داشته باشید. از شما می خواهیم که دوره آموزش مقدماتی تا پیشرفته پایتون روکسو را مطالعه کرده و سپس به ادامه این آموزش بپردازید.
قبل از نصب هر بسته خارجی، یک محیط مجازی برای پروژه خود ایجاد کنید. محیط مجازی جدید خود را فعال کنید، سپس دستور زیر را در ترمینال خود تایپ کنید تا کتابخانه requests نصب شود:
(venv) $ python -m pip install requests
سپس یک فایل جدید را در ویرایشگر متن مورد علاقه خود باز کنید. تنها چیزی که برای بازیابی HTML نیاز دارید چند خط کد است:
import requests URL = "https://realpython.github.io/fake-jobs/" page = requests.get(URL) print(page.text)
این کد یک درخواست GET را به URL داده شده ارسال می کند. داده های HTML را که سرور ارسال می کند بازیابی می کند و آن داده ها را در یک شی پایتون ذخیره می کند.
اگر اتریبیوت .text صفحه را پرینت کنید، متوجه خواهید شد که دقیقا شبیه HTML ای است که قبلا با developer tools مرورگر خود بررسی کرده اید. شما با موفقیت محتوی سایت ثابت را از اینترنت دریافت کردید! اکنون از داخل اسکریپت پایتون به HTML سایت دسترسی دارید.
استخراج اطلاعات وب سایت های استاتیک
وبسایتی که در این آموزش مینویسید، محتوی HTML ایستا را ارائه میکند. در این جا، سروری که سایت را میزبانی میکند، داکیومنت های HTML را که قبلا حاوی تمام دادههایی بوده است که کاربر میتوانسته ببیند، ارسال میکند.
قبلا که صفحه را با developer tools بررسی کردید، متوجه شدید که یک آگهی شغلی دارای یک HTML طولانی و نامرتب مانند زیر است:
<div class="card">
<div class="card-content">
<div class="media">
<div class="media-left">
<figure class="image is-48x48">
<img
src="https://files.realpython.com/media/real-python-logo-thumbnail.7f0db70c2ed2.jpg"
alt="Real Python Logo"
/>
</figure>
</div>
<div class="media-content">
<h2 class="title is-5">Senior Python Developer</h2>
<h3 class="subtitle is-6 company">Payne, Roberts and Davis</h3>
</div>
</div>
<div class="content">
<p class="location">Stewartbury, AA</p>
<p class="is-small has-text-grey">
<time datetime="2021-04-08">2021-04-08</time>
</p>
</div>
<footer class="card-footer">
<a
href="https://www.realpython.com"
target="_blank"
class="card-footer-item"
>Learn</a
>
<a
href="https://realpython.github.io/fake-jobs/jobs/senior-python-developer-0.html"
target="_blank"
class="card-footer-item"
>Apply</a
>
</footer>
</div>
</div>
درک یک بلوک طولانی، کد HTML می تواند چالش برانگیز باشد. برای آسانتر شدن خواندن این فایل، میتوانید از فرمت کننده HTML برای خوانایی بهتر آن استفاده کنید. خوانایی خوب به شما کمک می کند ساختار هر بلوک کد را بهتر درک کنید. اگرچه ممکن است به بهبود قالب بندی HTML کمک کند یا حتی نکند، اما همیشه ارزش امتحان کردن را دارد.
توجه: به خاطر داشته باشید که هر وب سایتی متفاوت خواهد بود. به همین دلیل است که قبل از حرکت به جلو، لازم است ساختار سایتی را که در حال حاضر با آن کار می کنید، بررسی و درک کنید.
HTML ای که با آن مواجه می شوید گاهی گیج کننده خواهد بود. خوشبختانه، HTML این بورد شغلی دارای نام کلاس های توصیفی بر روی المنت هایی است که لازم داریم:
"class="title is-5"حاوی عنوان آگهی استخدام است."class="subtitle is-6 companyحاوی نام شرکتی است که این موقعیت را ارائه می دهد."class="locationحاوی مکانی است که می خواهید در آن کار کنید.
اگر هنگام کار با HTML سر در گم شدید، به یاد داشته باشید که همیشه می توانید به مرورگر خود بازگردید و از ابزارهای توسعه دهنده برای بررسی بیشتر ساختار HTML به صورت تعاملی استفاده کنید.
تاکنون، شما با موفقیت از قدرت و طراحی کاربرپسند کتابخانه requests پایتون استفاده کردید. تنها با چند خط کد، توانستید محتوی HTML ایستا را از وب حذف کنید و آن را برای پردازش بیشتر در دسترس قرار دهید.
با این حال، موقعیت های چالش برانگیز تری وجود دارد که ممکن است هنگام وب اسکرپینگ سایت ها با آنها مواجه شوید. قبل از اینکه یاد بگیرید چگونه اطلاعات مربوطه را از HTML که به تازگی اسکرپ داده اید انتخاب کنید، نگاهی گذرا به دو مورد از این موقعیت های چالش برانگیزتر بیندازید.
استخراج اطلاعات وب سایت های مخفی
برخی از صفحات حاوی اطلاعاتی هستند که در پشت ورود به سیستم پنهان شده است. یعنی شما به یک حساب کاربری نیاز دارید تا بتوانید هر چیزی را از صفحه پاک کنید. فرآیند ایجاد یک درخواست HTTP از اسکریپت پایتون با نحوه دسترسی شما به یک صفحه از مرورگر متفاوت است. فقط به این دلیل که می توانید از طریق مرورگر خود وارد صفحه شوید، به این معنی نیست که می توانید آن را با اسکریپت پایتون خود اسکرپ کنید.
با این حال، کتابخانه requests دارای تونایی داخلی برای رسیدگی به احراز هویت (Authentication) است. با استفاده از این تکنیکها، میتوانید هنگام درخواست HTTP از اسکریپت پایتون خود، وارد وبسایتها شوید و سپس اطلاعاتی را که در پشت لاگین کردن پنهان است پاک کنید. برای دسترسی به اطلاعات بورد کار نیازی به ورود به سیستم ندارید، به همین دلیل است که این آموزش احراز هویت را پوشش نمی دهد.
استخراج اطلاعات وب سایت های پویا
در این آموزش، نحوه اسکرپ کردن یک وب سایت استاتیک را خواهید آموخت. کار با سایت های استاتیک ساده است زیرا سرور یک صفحه HTML را برای شما ارسال می کند که از قبل حاوی تمام اطلاعات صفحه در پاسخ است. می توانید آن پاسخ HTML را تجزیه کنید و بلافاصله شروع به انتخاب داده های مربوطه کنید.
از طرف دیگر، با یک وب سایت پویا، سرور ممکن است اصلا HTML را ارسال نکند. در عوض، می توانید کد جاوا اسکریپت را به عنوان پاسخ دریافت کنید. این کد با آنچه که هنگام بازرسی صفحه با ابزارهای توسعه دهنده مرورگر خود دیدید، کاملا متفاوت به نظر می رسد.
توجه: در این آموزش، اصطلاح وب سایت پویا به وب سایتی اطلاق می شود که HTML مشابهی را که هنگام مشاهده صفحه در مرورگر خود مشاهده می کنید، بر نمی گرداند.
بسیاری از وب اپلیکیشن های مدرن برای ارائه عملکرد خود با همکاری مرورگرهای کلاینت ها طراحی شده اند. این برنامه ها به جای ارسال صفحه های HTML، کد جاوا اسکریپت را ارسال می کنند که به مرورگر شما دستور می دهد تا HTML مورد نظر را ایجاد کند. وب اپلیکیشن ها محتوا پویا را به این روش ارائه میکنند تا محتوا را از سرور به کلاینت ها بتوانند دانلود کنند و همچنین از دانلود دوباره صفحه جلوگیری کنند و تجربه کلی کاربر را بهبود بخشند.
آنچه در مرورگر اتفاق می افتد با آنچه در اسکریپت شما اتفاق می افتد یکسان نیست. مرورگر شما کد جاوا اسکریپتی را که از سرور دریافت میکند اجرا میکند و DOM و HTML را برای شما به صورت local ایجاد میکند. با این حال، اگر یک وب سایت پویا در اسکریپت پایتون خود درخواست کنید، محتوی صفحه HTML را دریافت نخواهید کرد.
هنگامی که از requests استفاده می کنید، فقط آنچه را که سرور ارسال می کند دریافت می کنید. در مورد یک وب سایت پویا، به جای HTML با مقداری کد جاوا اسکریپت مواجه خواهید شد. تنها راه بدیل کد جاوا اسکریپتی به محتویی که به آن علاقه دارید، اجرای کد است، درست مانند کاری که مرورگر انجام میدهد. کتابخانه requests نمی تواند این کار را برای شما انجام دهد، اما راه حل های دیگری نیز وجود دارد.
به عنوان مثال، requests-html پروژهای است که توسط نویسنده کتابخانه requests ایجاد شده است و به شما امکان میدهد جاوا اسکریپت را با استفاده از سینتکسی شبیه به سینتکس requests ایجاد کنید. همچنین دارای قابلیت تجزیه داده ها با استفاده از Beautiful Soup است.
توجه: یکی دیگر از گزینه های محبوب برای اسکرپ کردن محتوی پویا، Selenium است. شما می توانید Selenium را به عنوان یک مرورگر کوچک در نظر بگیرید که قبل از ارسال پاسخ HTML به اسکریپت شما، کد جاوا اسکریپت را برای شما اجرا می کند.
شما در این آموزش بیشتر از این با اسکرپ کردن محتوی تولید شده به صورت پویا آشنا نخواهید شد. اکنون، کافی است به یاد داشته باشید در صورت نیاز به اسکرپ کردن یک وب سایت پویا، به یکی از گزینه های ذکر شده در بالا نگاه کنید.
مرحله 3: تجزیه کد HTML با Beautiful Soup
شما با موفقیت اندکی کد HTML را از اینترنت پاک کردهاید، اما وقتی به آن نگاه میکنید، به نظر یک آشفتگی بزرگ به نظر میرسد. هزاران المنت HTML وجود دارند، هزاران ویژگی بدون کاربرد موجود است و نمیدانیم آیا جاوا اسکریپت نیز در آن به کار برده شده است یا نه؟ وقت آن رسیده است که این کد طولانی را با کمک پایتون تجزیه و تحلیل کنید تا آن را قابل استفاده تر کنید و داده های مورد نظر خود را انتخاب کنید.
Beautiful Soup یک کتابخانه پایتون برای تجزیه داده های ساخت یافته است. این کتابخانه به شما امکان می دهد تا با HTML به روشی مشابه تعامل با یک صفحه وب با استفاده از ابزارهای توسعه دهنده تعامل داشته باشید. این کتابخانه چند توابع بصری دارد که می توانید از آنها برای کاوش HTML دریافتی خود استفاده کنید. برای شروع، از ترمینال خود برای نصب Beautiful Soup استفاده کنید:
(venv) $ python -m pip install beautifulsoup4
سپس، کتابخانه را در اسکریپت پایتون خود ایمپورت کنید و یک شی Beautiful Soup ایجاد کنید:
import requests from bs4 import BeautifulSoup URL = "https://realpython.github.io/fake-jobs/" page = requests.get(URL) soup = BeautifulSoup(page.content, "html.parser")
وقتی دو خط کد هایلایت شده در بالا را به کدها اضافه میکنید، یک شی Beautiful Soup ایجاد میکنید که page.content را که همان محتوی HTML است به عنوان ورودی میگیرد.
توجه: برای جلوگیری از مشکل رمزگذاری کاراکتر، میتوانید page.content را به جای page.text به کار ببرید. ویژگی content. بایتهای خام را در خود نگه میدارد که میتوانند بهتر از نمایش متنی که قبلا با استفاده از ویژگی متن چاپ کردهاید رمزگشایی شوند.
آرگومان دوم، "html.parser"، اطمینان حاصل می کند که از تجزیه کننده مناسب برای محتوی HTML استفاده می کنید.
پیدا کردن المنت ها با ID
در یک صفحه HTML، هر المنت می تواند یک ویژگی id اختصاصی داشته باشد. همانطور که از نام آن پیدا است، این ویژگی id باعث می شود المنت به طور منحصر به فرد در صفحه قابل شناسایی باشد. می توانید با انتخاب یک المنت خاص با ID آن، تجزیه صفحه خود را شروع کنید.
به ابزارهای توسعهدهنده برگردید و شی HTML را که حاوی تمام آگهیهای شغلی است شناسایی کنید. با نگه داشتن موس روی قسمتهایی از صفحه و کلیک راست برای بازرسی، کاوش کنید.
توجه: این کمک می کند که به صورت دوره ای به مرورگر خود برگردید و به صورت تعاملی صفحه را با استفاده از ابزارهای توسعه دهنده کاوش کنید و یاد بگیرید چگونه المنت های دقیق مورد نظر خود را پیدا کنید.
المنتی که به دنبال آن هستید یک <div> با ویژگی id است که دارای مقدار "ResultsContainer" است. ویژگی های دیگری نیز دارد، اما در زیر خلاصه آنچه شما به دنبال آن هستید آمده است:
<div id="ResultsContainer"> <!-- all the job listings --> </div>
Beautiful Soup به شما امکان می دهد المنت HTML خاص را با id آن پیدا کنید:
results = soup.find(id="ResultsContainer")
برای مشاهده راحتتر، میتوانید هر شی Beautiful Soup را هنگام چاپ آن را زیباتر کنید. اگر .prettify() را برای متغیر results که در بالا تعریف کردهاید فراخوانی کنید، آنگاه تمام HTML موجود در <div> را خواهید دید:
print(results.prettify())
وقتی از id المنت استفاده می کنید، می توانید یک المنت را از بین همه المنت های دیگر HTML انتخاب کنید. اکنون می توانید فقط با این بخش خاص از HTML صفحه کار کنید. به نظر می رسد soup کمی نازک تر شده است! با این حال، هنوز کاملا متراکم است.
استخراج اطلاعات المنت ها بر اساس نام کلاس HTML
دیدهاید که هر آگهی شغلی در یک المنت <div> با محتوی کارت کلاس مرتبط شده است. اکنون می توانید با شی جدید خود به نام results کار کنید و فقط آگهی های شغلی موجود در آن را انتخاب کنید. به هر حال اینها بخش هایی از HTML هستند که به آنها علاقه مند هستید! می توانید این کار را در یک خط کد زیر انجام دهید:
job_elements = results.find_all("div", class_="card-content")
در اینجا، شما ()find_all. را برای یک شی Beautiful Soup فراخوانی می کنید، که یک iterable حاوی تمام لیست های شغلی نمایش داده شده در آن صفحه را برمی گرداند.
به همه آنها نگاهی بیندازید:
for job_element in job_elements:
print(job_element, end="\n"*2)
نتیجه به دست آمده در حال حاضر بسیار منظم است، اما هنوز مقدار زیادی HTML دارد! قبلا دیدید که صفحه شما برای بعضی از المنت ها دارای نام های توصیفی برای کلاس ها است. می توانید المنت ها را از هر موقعیت شغلی با .find() پیدا کنید:
for job_element in job_elements:
title_element = job_element.find("h2", class_="title")
company_element = job_element.find("h3", class_="company")
location_element = job_element.find("p", class_="location")
print(title_element)
print(company_element)
print(location_element)
print()
هر job_element یک شی ()BeautifulSoup است. بنابراین، میتوانید همان متدهایی را که روی نتایج به دست آمده از المنت والد آن انجام دادید، برای آن استفاده کنید.
با این قطعه کد، به دادههایی که واقعا به آنها علاقه دارید نزدیکتر و نزدیکتر میشوید.
<h2 class="title is-5">Senior Python Developer</h2> <h3 class="subtitle is-6 company">Payne, Roberts and Davis</h3> <p class="location">Stewartbury, AA</p>
در مرحله بعد، یاد خواهید گرفت که چگونه این خروجی را محدود کنید تا فقط به محتوی متنی مورد علاقه خود دسترسی داشته باشید.
استخراج متن از المنت های HTML با پایتون
شما فقط می خواهید عنوان، شرکت و مکان هر موقعیت شغلی را ببینید. Beautiful Soup این امکان را به شما میدهد. شما می توانید متن را به یک شی Beautiful Soup اضافه کنید تا فقط محتوی متنی المنت ها HTML را که شی حاوی آن است برگردانید:
for job_element in job_elements:
title_element = job_element.find("h2", class_="title")
company_element = job_element.find("h3", class_="company")
location_element = job_element.find("p", class_="location")
print(title_element.text)
print(company_element.text)
print(location_element.text)
print()
قطعه کد بالا را اجرا کنید آنگاه متن هر المنت را خواهید دید. با این حال، این امکان وجود دارد که مقداری فضای خالی اضافی نیز دریافت کنید. از آنجایی که اکنون با رشته های پایتون کار می کنید، می توانید فضای خالی اضافی را .strip() کنید. همچنین می توانید از هر متد رشته پایتون برای بهتر کردن متن خود استفاده کنید:
for job_element in job_elements:
title_element = job_element.find("h2", class_="title")
company_element = job_element.find("h3", class_="company")
location_element = job_element.find("p", class_="location")
print(title_element.text.strip())
print(company_element.text.strip())
print(location_element.text.strip())
print()
نتایج در نهایت بسیار بهتر به نظر می رسند:
Senior Python Developer Payne, Roberts and Davis Stewartbury, AA Energy engineer Vasquez-Davidson Christopherville, AA Legal executive Jackson, Chambers and Levy Port Ericaburgh, AA
این یک لیست قابل خواندن از مشاغل است که شامل نام شرکت و مکان هر شغل نیز می شود. با این حال، شما بهدنبال موقعیتی بهعنوان توسعهدهنده نرمافزار هستید و این نتایج شامل آگهیهای شغلی در بسیاری از زمینههای دیگر نیز میشود.
پیدا کردن المنت ها بر اساس نام کلاس و محتوی متنی
همه لیست های شغلی شامل مشاغل توسعه دهنده نیستند. به جای چاپ تمام کارهای فهرست شده در سایت، ابتدا آنها را با استفاده از کلمات کلیدی فیلتر کنید.
می دانید که عنوان شغل در صفحه HTML در المنت های <h2> نگهداری می شود. برای فیلتر کردن کارهای خاص، می توانید از آرگومان رشتهای استفاده کنید:
python_jobs = results.find_all("h2", string="Python")
این کد همه المنتهای <h2> را پیدا می کند که در آن رشته موجود دقیقا با "Python" مطابقت دارد. توجه داشته باشید که شما به طور مستقیم متد را برای متغیر results خود فراخوانی می کنید. اگر ادامه دهید و خروجی قطعه کد بالا را در کنسول خود چاپ کنید، ممکن است ناامید شوید زیرا خالی خواهد بود:
>>> print(python_jobs) []
یک شغل مربوط به پایتون در نتایج جستجو وجود داشت، پس چرا این شغل نمایش داده نمی شود؟
همانطور که در بالا دیدید وقتی از =string استفاده می کنید، برنامه شما دقیقا آن رشته را جستجو می کند. هر گونه تفاوت در املا، حروف بزرگ یا فضای خالی از پیدا شدن المنت جلوگیری می کند. در بخش بعدی، راهی برای جستجوی بهتر رشته خود پیدا خواهید کرد.
فرستادن یک تابع به یکی از متدهای Beautiful Soup
علاوه بر رشته ها، گاهی اوقات می توانید توابعی را به عنوان آرگومان به متدهای Beautiful Soup بفرستید. می توانید خط قبلی کد را تغییر دهید تا به جای آن از یک تابع استفاده کنید:
python_jobs = results.find_all(
"h2", string=lambda text: "python" in text.lower()
)
اکنون یک تابع anonymous را به آرگومان string= بفرستید. تابع lambda به متن هر المنت <h2> نگاه می کند، آن را به حروف کوچک تبدیل می کند و بررسی می کند که آیا زیر رشته "python" در جایی یافت می شود یا خیر. می توانید بررسی کنید که آیا موفق به شناسایی همه مشاغل پایتون با این روش شده اید یا خیر:
>>> print(len(python_jobs)) 10
برنامه شما 10 موقعیت شغلی مناسب را پیدا کرده است که در عنوان شغلی آنها کلمه "python" وجود دارد!
یافتن المنت ها با توجه به محتوی متنی که دارند، یک راه قدرتمند برای فیلتر کردن پاسخ HTML شما برای اطلاعات خاص است. Beautiful Soup به شما امکان می دهد از رشته ها یا توابع به عنوان آرگومان برای فیلتر کردن متن در اشیا Beautiful Soup استفاده کنید.
به نظر می رسد این لحظه خوبی برای اجرای حلقه for و چاپ عنوان، مکان و اطلاعات شرکت مربوط به شغلهای مربوط به پایتون است که شناسایی کرده اید:
# ...
python_jobs = results.find_all(
"h2", string=lambda text: "python" in text.lower()
)
for job_element in python_jobs:
title_element = job_element.find("h2", class_="title")
company_element = job_element.find("h3", class_="company")
location_element = job_element.find("p", class_="location")
print(title_element.text.strip())
print(company_element.text.strip())
print(location_element.text.strip())
print()
با این حال، وقتی سعی میکنید اسکرپر خود را برای چاپ کردن اطلاعات شغلهای فیلتر شده پایتون اجرا کنید، با خطا مواجه میشوید:
AttributeError: 'NoneType' object has no attribute 'text'
این پیام یک خطای متداول است که هنگام اسکرپ کردن اطلاعات از اینترنت با آن مواجه خواهید شد. HTML یک المنت را در لیست python_jobs خود بررسی کنید. چه شکلی است؟ به نظر شما خطا از کجا می آید؟
شناسایی شرایط خطا
وقتی به یک المنت در python_jobs نگاه میکنید، میبینید که فقط از المنت های <h2> تشکیل شده است که شامل عنوان شغل است:
<h2 class="title is-5">Senior Python Developer</h2>
هنگامی که کد انتخاب شده را بازبینی میکنید، میبینید این همان چیزی است که شما هدف قرار دادهاید. شما فقط المنت های <h2> که همان عنوان مشاغل شامل کلمه "python" هستند، را فیلتر کردید. همانطور که می بینید، این المنت ها بقیه اطلاعات مربوط به کار را شامل نمی شود.
پیام خطایی که قبلا دریافت کردید به صورت زیر بود:
AttributeError: 'NoneType' object has no attribute 'text'
شما سعی کردید عنوان شغل، نام شرکت و مکان شغل را در هر المنت در python_jobs پیدا کنید، اما هر المنت فقط حاوی عنوان شغل است.
کتابخانه parser همچنان به دنبال موارد دیگر نیز میگردد و None را برمیگرداند زیرا نمیتواند آنها را پیدا کند. سپس، print() زمانی که می خواهید ویژگی .text را از یکی از این اشیا None استخراج کنید، با نشان دادن یک پیغام خطا با شکست مواجه می شود.
متنی که به دنبال آن هستید در المنت های Siblings المنت های <h2> که فیلتر کردن برگردانده است، نهفته است. Beautiful Soup می تواند به شما در انتخاب المنت ها Siblings، children و parents هر شی Beautiful Soup کمک کند.
دسترسی به المنت های Parent
یکی از راه های دسترسی به تمام اطلاعات مورد نیاز این است که در سلسله مراتب DOM با شروع از المنت های <h2> که شناسایی کرده اید، قدم بردارید. نگاهی دیگر به یک آگهی شغلی بیاندازید. المنت <h2> را که حاوی عنوان شغلی است و همچنین نزدیکترین المنت parent آن که حاوی تمام اطلاعات مورد علاقه شما است را بیابید:
<div class="card">
<div class="card-content">
<div class="media">
<div class="media-left">
<figure class="image is-48x48">
<img
src="https://files.realpython.com/media/real-python-logo-thumbnail.7f0db70c2ed2.jpg"
alt="Real Python Logo"
/>
</figure>
</div>
<div class="media-content">
<h2 class="title is-5">Senior Python Developer</h2>
<h3 class="subtitle is-6 company">Payne, Roberts and Davis</h3>
</div>
</div>
<div class="content">
<p class="location">Stewartbury, AA</p>
<p class="is-small has-text-grey">
<time datetime="2021-04-08">2021-04-08</time>
</p>
</div>
<footer class="card-footer">
<a
href="https://www.realpython.com"
target="_blank"
class="card-footer-item"
>Learn</a
>
<a
href="https://realpython.github.io/fake-jobs/jobs/senior-python-developer-0.html"
target="_blank"
class="card-footer-item"
>Apply</a
>
</footer>
</div>
</div>
المنت <div> با کلاس card-content حاوی تمام اطلاعات مورد نظر شما است. این المنت یک parent سطح سوم برای المنت عنوان <h2> است که با استفاده از فیلتر خود پیدا کردید.
با در نظر گرفتن این اطلاعات، اکنون می توانید از المنت های موجود در python_jobs استفاده کنید و به جای آن، المنت ها نیای آنها را واکشی کنید تا به تمام اطلاعاتی که می خواهید دسترسی داشته باشید:
python_jobs = results.find_all(
"h2", string=lambda text: "python" in text.lower()
)
python_job_elements = [
h2_element.parent.parent.parent for h2_element in python_jobs
]
شما یک لیست را اضافه کردهاید که بر روی هر یک از المنت های عنوان <h2> در python_jobs که با فیلتر کردن با عبارت lambda به دست آوردهاید، عمل میکند. شما در حال انتخاب المنت parent المنت parent المنت parent هر المنت عنوان <h2> هستید. این در واقع انتخاب سه نسل بالاتر است!
وقتی به HTML یک موقعیت شغلی نگاه میکردید، متوجه میشوید که این المنت parent، تمام اطلاعات مورد نیاز شما را در بر میگیرد.
اکنون می توانید کد موجود در حلقه for خود را برای تکرار روی المنت ها والد منطبق کنید:
for job_element in python_job_elements:
# -- snip --
وقتی اسکریپت خود را بار دیگر اجرا کنید، خواهید دید که کد شما یک بار دیگر به تمام اطلاعات مربوطه دسترسی دارد. دلیل آن این است که شما اکنون به جای المنت های <h2> روی المنت های <div class="card-content"> حلقه می زنید.
استفاده از ویژگی parent. که هر شی Beautiful Soup با آن ارائه میشود، راهی دیداری برای گذر از ساختار DOM خود و آدرس دادن به المنت های مورد نیاز به شما میدهد. همچنین می توانید به المنت های فرزند و المنت های Siblings به روشی مشابه دسترسی داشته باشید. برای اطلاعات بیشتر، پیمایش درخت را بخوانید.
استخراج اطلاعات اتریبیوت ها از المنت های HTML
در این مرحله، اسکریپت پایتون شما قبلا سایت را اسکرپ کرده است و HTML آن را برای آگهی های شغلی مرتبط فیلتر می کند. آفرین! با این حال، چیزی که هنوز وجود ندارد، لینک درخواست شغل است.
اگر صفحه را بررسی کنید، دو لینک در پایین هر کارت پیدا خواهید کرد. اگر المنت های لینک را به همان روشی که سایر المنت ها را مدیریت می کنید، مدیریت کنید، URL های مورد علاقه خود را دریافت نخواهید کرد:
for job_element in python_job_elements:
# -- snip --
links = job_element.find_all("a")
for link in links:
print(link.text.strip())
اگر این قطعه کد را اجرا کنید، به جای URL های مرتبط، متن لینک های Learn و Apply را دریافت خواهید کرد.
دلیل آن این است که اتریبیوت .text فقط محتوی قابل مشاهده یک المنت HTML را باقی می گذارد. تمام تگهای HTML از جمله ویژگیهای HTML حاوی URL را حذف میکند و فقط متن لینک را برای شما باقی میگذارد. برای دریافت URL به جای آن، باید مقدار یکی از ویژگی های HTML را به جای کنار گذاشتن استخراج کنید.
URL تگ a با ویژگی href مرتبط است. URL خاصی که به دنبال آن هستید، مقدار ویژگی href تگ دوم <a> در پایین HTML یک موقعیت شغلی واحد است:
<!-- snip -->
<footer class="card-footer">
<a href="https://www.realpython.com" target="_blank"
class="card-footer-item">Learn</a>
<a href="https://realpython.github.io/fake-jobs/jobs/senior-python-developer-0.html"
target="_blank"
class="card-footer-item">Apply</a>
</footer>
</div>
</div>
با واکشی تمام المنت های <a>در یک کارت شغلی شروع کنید. سپس، مقدار ویژگی های href آنها را با استفاده از براکت [ ] استخراج کنید:
for job_element in python_job_elements:
# -- snip --
links = job_element.find_all("a")
for link in links:
link_url = link["href"]
print(f"Apply here: {link_url}\n")
در این قطعه کد، ابتدا همه لینک ها را از هر یک از آگهیهای شغلی فیلتر شده دریافت کنید. سپس ویژگی href را که حاوی URL است با استفاده از ["href"] استخراج کرده و در کنسول خود چاپ کنید.
در بلوک تمرین زیر، میتوانید دستورالعملهایی را برای چالش برای اصلاح نتایج پیوندی که دریافت کردهاید بیابید:

برای خواندن راه حل احتمالی برای این تمرین روی بلوک راه حل کلیک کنید:
شما می توانید از براکت برای استخراج سایر ویژگی های HTML نیز استفاده کنید.
به تمرین ادامه دهید
اگر همراه با خواندن این مقاله کد آن را هم نوشته اید، می توانید اسکریپت خود را همانطور که هست اجرا کنید و اطلاعات فیک مربوط به کار را در ترمینال خود مشاهده کنید کرد. قدم بعدی شما این است که با یک بورد شغلی واقعی روبهرو شوید! برای ادامه تمرین مهارتهای خود، با استفاده از یکی یا همه سایتهای زیر، دوباره فرآیند اسکرپینگ را به عنوان تمرین انجام دهید:
وب سایت های داده شده نتایج جستجوی خود را به عنوان پاسخ های HTML ایستا، شبیه به صفحه شغلی پایتون، برمی گرداند. بنابراین، می توانید آنها را فقط با استفاده از requests و Beautiful Soup اسکرپ کنید.
با استفاده از یکی از این سایتها، دوباره این آموزش را از بالا بخوانید. خواهید دید که ساختار هر وب سایت متفاوت است و باید کد را به روشی متفاوت بازسازی کنید تا استخراج اطلاعات داده های مورد نظر خود را دریافت کنید. مقابله با این چالش راهی عالی برای تمرین مفاهیمی است که به تازگی آموخته اید. در حالی که ممکن است وقت شما را بگیرد، ولی در عوض مهارت های کدنویسی شما را قوی تر خواهد کرد!
در تمرین های خود، همچنین می توانید ویژگی های اضافی Beautiful Soup را کشف کنید. از مستندات این پکیچ به عنوان کتاب راهنما استفاده کنید. تمرین اضافی به شما کمک میکند تا با استفاده از پایتون، در requests و Beautiful Soup برای استخراج اطلاعات از وب سایت با پایتون مهارت بیشتری پیدا کنید.
برای پایان دادن به سفر خود در استخراج اطلاعات از وب سایت با پایتون، می توانید کد خود را ویرایش کنید و یک برنامه رابط خط فرمان (CLI) ایجاد کنید که یکی از کارتهای وب سایت کاریابی را اسکرپ میکند و نتایج را با یک کلمه کلیدی که می توانید در هر اجرا وارد کنید فیلتر می کند. ابزار CLI شما می تواند به شما اجازه دهد انواع خاصی از مشاغل را در مکان های خاص جستجو کنید.
نتیجه گیری
کتابخانه requests راهی کاربرپسند برای واکشی HTML ایستا از اینترنت با استفاده از پایتون به شما می دهد. سپس می توانید HTML را با بسته دیگری به نام Beautiful Soup تجزیه کنید. هر دو بسته، همراهان قابل اعتماد و مفیدی برای وب اسکرپینگ هستند. متوجه خواهید شد که Beautiful Soup بیشتر نیازهای تجزیه و تحلیل شما را برآورده می کند، از جمله پیمایش و جستجوی پیشرفته.
در این آموزش، یاد گرفتید که چگونه داده ها را از وب با استفاده از Python، requests و Beautiful Soup پاک کنید. شما یک اسکریپت ساختید که آگهیهای شغلی را از اینترنت دریافت میکند و از ابتدا تا انتها فرآیند کامل وب اسکرپینگ را طی کردید.
شما یاد گرفتید که چگونه:
- استخراج اطلاعات را از ابتدا تا انتها با اسکرپ وب پیمایش کنید
- ساختار HTML سایت خود را با ابزارهای توسعه دهنده مرورگر خود بررسی کنید
- داده های کدگذاری شده در URL ها را رمزگشایی کنید
- محتوی HTML صفحه را با استفاده از کتابخانه requests دانلود کنید
- برای استخراج اطلاعات مرتبط، HTML دانلود شده را با Beautiful Soup تجزیه کنید
- اسکریپتی بسازید که پیشنهادهای شغلی را از وب واکشی کند و اطلاعات مرتبط را در کنسول شما نمایش دهد
با در نظر گرفتن این دو کتابخانه قدرتمند، می توانید ادامه کار خود را دهید و ببینید چه وب سایت های دیگری را می توانید اسکرپ کنید. از آن لذت ببرید.
منبع: وب سایت RealPython










در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.