روابط بین دادهای در MongoDB - روابط یک به یک
Relationships Between Data in MongoDB - Part 1
06 بهمن 1400

همانطور که در قسمت قبل توضیح داده شد برخی از داده ها همیشه به هم مربوط هستند، البته تمام مباحثی که در جلسه قبل بررسی کردیم مربوط به یک collection یا یک document بود اما بحث این جلسه به ارتباط بین این collection ها یا document ها می پردازد. در برنامه های واقعی معمولاً چندین collection و ده ها یا شاید صدها و هزاران document داشته باشیم. زمانی که چندین document داریم که با یکدیگر به نزدیکی در ارتباط هستند، باید به مسئله ای توجه کنیم: نحوه ذخیره سازی آن ها به چه صورت خواهد بود؟ ما چطور می توانیم این داده ها را به صورتی بهینه ذخیره کنیم که در عین حال با یکدیگر مرتبط باشند؟
فرض کنید که یک وب سایت فروشگاهی داشته باشیم. ما در این وب سایت اطلاعاتی از قبیل نام محصول، توضیحات محصول، نام کاربر و آدرس کاربر را خواهیم داشت. از بین تمام این داده ها نام کاربر و آدرس کاربر به نردیکی با یکدیگر در ارتباط هستند. حالا چطور باید آن ها را در ارتباط با یکدیگر ذخیره کنیم؟ معمولاً در پایگاه داده MongoDB دو راه برای انجام این کار (یعنی برقراری ارتباط بین داده ها) وجود دارد: روش اول استفاده از document های تو در تو (embedded documents) و روش دوم استفاده از reference ها (به معنی ارجاعات) است.
شما نمونه هر دوی این روش ها را در تصویر زیر مشاهده می کنید:
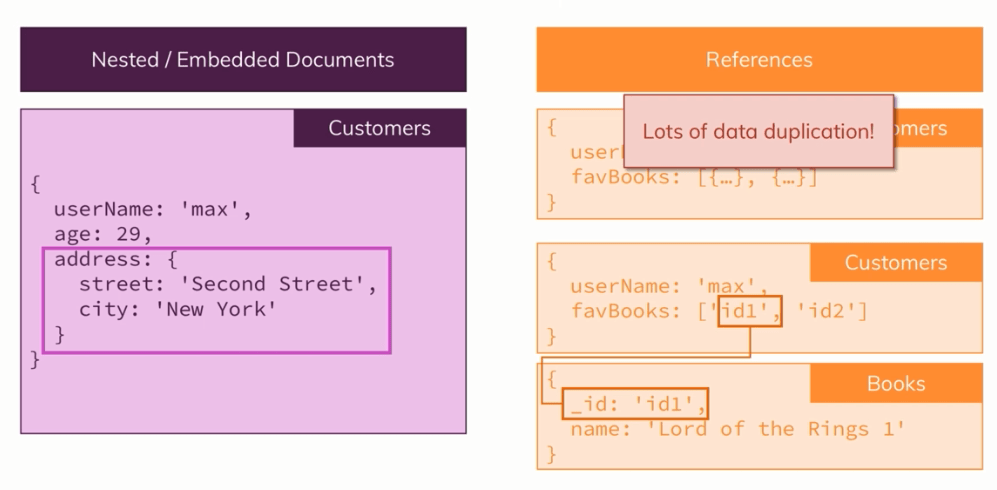
در روش اول که همان document های تو در تو می باشد، باید اطلاعات مربوط به هم را درون یک document یا شیء ذخیره کنیم. البته در مورد تصویر بالا باید توضیح بدهم که نام خصوصیات تمام اشیاء جیسون درون double quotation قرار می گیرند اما من می خواستم که خواندن کد ساده تر شود به همین دلیل آن ها را نگذاشته ام. همانطور که در این مثال مشاهده می کنید آدرس کاربر به شدت به خود کاربر وابسته است بنابراین آن را به صورت nest شده یا تو در تو درون شیء اصلی نگهدارنده کاربر قرار داده ام. دلیل این کار این است که اگر داده هایی با یکدیگر مرتبط باشند، احتمال دریافت آن ها با یکدیگر بالا می رود. بنابراین اگر هر دو را درون یک شی داشته باشم می توانم به راحتی تمام اطلاعات کاربر را یکجا دریافت کنم، در غیر این صورت مجبور به استفاده از دستورات جوین و دستورات پیچیده دیگر برای ادغام چند کوئری هستم.
همانطور که در تصویر بالا مشاهده می شود، روش دیگر حل این مشکل استفاده از reference هاست. فرض کنید کاربران ما لیستی از کتاب های مورد علاقه خودشان را داشته باشند. من برای کوتاه شدن مثال، کتاب ها را به صورت سه نقطه گذاشته ام اما به راحتی متوجه می شوید که تمام کتاب ها درون یک آرایه ذخیره شده اند (اعضای این آرایه document های جداگانه ای هستند که هرکدام معادل یک کتاب و اطلاعات آن کتاب اند). این روش همان روشی است که در قسمت اول انجام دادیم (یعنی document های تو در تو) اما این روش در چنین مثالی به خوبی جواب نمی دهد. چرا؟ به دلیل اینکه ممکن است بسیاری از کاربران یک کتاب را به عنوان کتاب مورد علاقه خود انتخاب کند. در این صورت ما مجبور هستیم نام آن کتاب را مکرراً در فیلد های مختلف بیاوریم. مثلا شاهنامه کتاب مورد علاقه علی، رضا، شاهین، امیر، نسترن، منصور و غیره است و باید نام و اطلاعات آن کتاب برای تک تک این افراد ذکر شود. همچنین اگر بخواهیم چیزی در مورد آن کتاب را تغییر بدهیم (مثلا سال انتشار یا توضیحات) باید آن را برای تمام کاربران تغییر دهیم که عملیاتی بسیار کند و غیر بهینه می باشد. راه حل چیست؟
راه حل ما در چنین شرایطی استفاده از reference ها می باشد. برای این کار ابتدا به دو collection متفاوت نیاز داریم: یک collection به نام customers که همان خریداران یا کاربران ما خواهند بود و collection دیگر به نام books یا کتاب ها که حاوی لیستی از کتاب های مورد نظر ما می باشد. حالا به جای آن که اطلاعات هر کتاب را برای هر خریدار تکرار کنیم فقط یک id خاص از آن کتاب را در قسمت favbooks قرار می دهیم. احتمالاً می گویید با این کار مجبور به اجرای دو کوئری مختلف برای دریافت اطلاعات کتاب و کاربر هستیم. حرف شما درست است اما اگر قرار باشد اطلاعات کتاب را تغییر بدهیم نیازی نیست هزاران هزار document مختلف را ویرایش کنیم و پایگاه داده را درگیر یک عملیات سنگین نماییم. در طرف دیگر، اگر از reference ها استفاده کنیم از آنجایی که id هیچ وقت تغییر نخواهد کرد، نیازی به ویرایش collection کاربران نداریم. سوالی که باقی می ماند این است که کدام روش، روش بهتری است و آیا اصلا روش بهتری وجود دارد؟
این موضوع را با یک مثال توضیح می دهم. فرض کنید قرار است یک وب سایت برای یک بیمارستان طراحی کنیم و در پایگاه داده آن، نام هر بیمار را با شرح بیماری خاص اش ذخیره سازی نماییم. بنابراین هر بیمار یک شرح بیماری دارد که مخصوص همان بیمار است و همین طور برای ساده تر شدن مثال فرض می کنیم که یک بیمار نمی تواند بیش از یک بیماری داشته باشد (ارتباط یک به یک).
برای شروع پایگاه داده خود را با dropDatabase پاک کنید تا از صفر شروع کنیم. در همان ابتدا پایگاه داده ای به نام hospital خواهیم داشت بنابراین:
use hospital
سپس collection ای به نام patients (بیماران) خواهیم داشت بنابراین:
db.patients.insertOne({name: "Amir", age: 24, diseaseSummary: "summary-amir-1"})
من می خواهم برای این مثال از روش reference استفاده کنم. در ضمن diseaseSummary یعنی خلاصه بیماری یا شرح بیماری. حالا برای مشاهده نتیجه دستور زیر را اجرا می کنیم:
db.patients.findOne()
نتیجه برگردانده شده به شکل زیر خواهد بود:
"_id" : ObjectId("5e87272368288536b120cb12"),
"name" : "Amir",
"age" : 24,
"diseaseSummary" : "summary-amir-1"
تا اینجا همه چیز خوب است. حالا یک collection دیگر به شکل زیر تعریف می کنیم:
db.diseaseSummaries.insertOne({_id: "summary-amir-1", diseases: ["cold", "broken leg"]})
diseaseSummaries قرار است شرح بیماری بیماران را در خود داشته باشد. من فرض می کنم مریضی های این بیمار cold (سرماخوردگی) و broken leg (شکستگی پا) می باشد و آن ها را به شکل بالا در آرایه قرار داده ام. نکته مهم این است که id را خودم تعیین کرده و روی summary-amir-1 گذاشته ام تا به صورت خودکار توسط MongoDB ایجاد نشود. این همان id است که در collection قبلی در disesaseSummary تعریف کرده بودیم. حالا برای نمایش آن می گویم:
db.diseaseSummaries.findOne()
نتیجه:
{ "_id" : "summary-amir-1", "diseases" : [ "cold", "broken leg" ] }
بنابراین همه چیز خوب کار می کند. حالا فرض کنید در قسمتی از برنامه باید بیمار و لیست مریضی هایش یا همان diseaseSummary را نمایش بدهیم. ما این برنامه را با PHP یا node.js یا Net. یا هر زبان دیگری نوشته ایم، قابلیت ذخیره سازی مقادیر را خواهیم داشت. در Shell هم می توانیم این کار را بکنیم:
var dsid = db.patients.findOne().diseaseSummary
با اجرای این کد هیچ اتفاقی در ترمینال نمی افتد اما اگر نام متغیر را به عنوان یک دستور اجرا کنیم، مقدار id برگردانده می شود:
dsid
نتیجه:
summary-amir-1
حالا در یک کوئری دیگر می گوییم:
db.diseaseSummaries.findOne({_id: dsid})
یعنی بر اساس این id مقدار را از collection دیگر گرفته ایم. مقدار برگردانده شده با اجرای این دستور به درستی و به شکل زیر است:
{ "_id" : "summary-amir-1", "diseases" : [ "cold", "broken leg" ] }
نکته منفی در اینجا این است که برای دریافت مقدار خود باید دو کوئری جداگانه را ثبت کنیم و همچنین اگر پایگاه داده ما بسیار بزرگ باشد، این روش خوبی نیست. در چنین حالت ساده ای، استفاده از embedded documents است. هر جا که رابطه 1 به 1 داریم (مانند بیمار و بیماری هایش) بهتر است از embedded document ها استفاده کنیم.
بگذارید روش بهتر را نشانتان بدهم. ابتدا داده های درون patients را حذف می کنم:
db.patients.deleteMany({})
سپس دوباره بیمار را اضافه می کنم اما از reference ها استفاده نخواهم کرد:
db.patients.insertOne({name: "Amir", age: 24, diseaseSummary: {diseases: ["cold", "broken leg"]}})
به همین شکل می توانیم آن ها را به صورت تو در تو قرار دهیم چرا که رابطه از نوع 1 به 1 است. حالا با یک دستور ساده findOne نتیجه را می بینیم:
"_id" : ObjectId("5e872d5f68288536b120cb15"),
"name" : "Amir",
"age" : 24,
"diseaseSummary" : {
"diseases" : [
"cold",
"broken leg"
]
}
}

مقالات مرتبط

06 اسفند 1400
آخرین سوالات کاربران
ما را دنبال کنید



در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.