Python حرفهای: مرحلهی دوم؛ پاکسازی داده
Professional Python: Data Cleansing
14 فروردین 1400

یادآوری و آماده سازی ابزار
در جلسه قبلی به شما توضیح دادم که چطور Jupyter Notebooks را نصب کنیم و چطور داده های خود را در آن بارگذاری کنیم. از آنجایی که می خواهیم با Jupyter Notebook ها کار کنیم باید برخی از مباحث این بخش را یادآوری کنم تا با ذهن تازه وارد مسئله شوید.
ما در ابتدا باید ابزار anaconda را نصب می کردیم. در صورتی که این کار را نکرده اید به جلسه قبل مراجعه کرده و طبق دستورالعمل آن، anaconda را نصب کنید. در صورتی که مطمئن نیستید anaconda روی سیستم شما نصب شده است یا خیر، باید ترمینال خود را باز کرده و دستور زیر را در آن اجرا کنید:
conda info
پس از اجرای این دستور باید نتیجه ای شبیه به نتیجه زیر برایتان چاپ شود:
active environment : base active env location : /home/amir/anaconda3 shell level : 1 user config file : /home/amir/.condarc populated config files : conda version : 4.9.2 conda-build version : 3.20.5 python version : 3.8.5.final.0 virtual packages : __glibc=2.32=0 __unix=0=0 __archspec=1=x86_64 base environment : /home/amir/anaconda3 (writable) channel URLs : https://repo.anaconda.com/pkgs/main/linux-64 https://repo.anaconda.com/pkgs/main/noarch https://repo.anaconda.com/pkgs/r/linux-64 https://repo.anaconda.com/pkgs/r/noarch package cache : /home/amir/anaconda3/pkgs /home/amir/.conda/pkgs envs directories : /home/amir/anaconda3/envs /home/amir/.conda/envs platform : linux-64 user-agent : conda/4.9.2 requests/2.24.0 CPython/3.8.5 Linux/5.8.0-43-generic ubuntu/20.10 glibc/2.32 UID:GID : 1000:1000 netrc file : None offline mode : False
اگر به جای گزارش بالا، خطا دریافت کنید یعنی مراحل نصب به درستی انجام نشده است و یا اینکه anaconda را اصلا نصب نکرده اید. در هر دو حالت باید طبق توضیحات جلسه قبل فرآیند نصب را دوباره انجام بدهید.
در مرحله بعدی به پکیج هایی مانند کتابخانه NumPy و کتابخانه Pandas و کتابخانه مشهور scikit-learn و کتابخانه matplotlib را نصب کردیم. نحوه نصب تمام این پکیج ها در جلسه قبل توضیح داده شده است. آخرین مرحله آماده سازی پیدا کردن یک data set یا مجموعه داده است. بهترین مکان برای پیدا کردن مجموعه داده ها وب سایت kaggle می باشد که مجموعه ای از متخصصان یادگیری ماشین است که Jupyter Notebook های خود را با دیگران به اشتراک می گذارند و با هم مسابقاتی را برگزار می کنند و dataset هایشان را نیز در این سایت قرار داده اند. شما باید به آدرس kaggle.com/karangadiya/fifa19 رفته و این data set را دانلود کنید.
ما چند دستور تمرینی را نیز اجرا کردیم. به طور مثال اگر بخواهیم اطلاعاتی کلی راجع به data frame خود داشته باشیم می توانیم کد زیر را در notebook خود اجرا کنیم:
import pandas as pd
data_frame = pd.read_csv('data.csv')
data_frame.shape
در صورتی که به خطا برخورد کردید آرگومان dtype (مشخص کردن نوع داده) را نیز پاس بدهید:
import pandas as pd
data_frame = pd.read_csv('data.csv', dtype='unicode')
data_frame.shape
با اجرای این کد نتیجه زیر را می گیریم:
(18208, 89)
یعنی داده های ما ۸۹ ستون و ۱۸۲۰۸ ردیف هستند. من کد بالا را نگه داشته و آن را ویرایش نمی کنم بلکه در کنار ردیف بعدی [] In شروع به نوشتن بقیه کدها می کنم.
نکته: در صورتی که سیستم شما ضعیف است و نمی توانید با این حجم از داده کار کنید، می توانید داده های موجود را از این آدرس یا از وب سایت kaggle دانلود کنید که اطلاعات مربوط به کشتی تایتانیک است. من در طول دوره از هر کدام مثال هایی را خواهم زد و روند کار یکی خواهد بود، با این حال شما می توانید از هر data set دیگری نیز استفاده کنید.
توصیف داده ها در Jupyter Notebook
ما تا این بخش دستور ساده shape را روی داده هایمان اجرا کرده ایم اما من input اول یا همان ردیف اول را حذف نمی کنم بلکه به سراغ ردیف بعدی می روم. هر ردیف با عبارت [] In مشخص شده است بنابرین مشاهده آن ساده است. نکته مهم اینجاست که داده های موجود در ردیف اول، در ردیف دوم نیز قبل دسترسی هستند بنابراین کدهای جدید هنوز به متغیری به نام data_frame دسترسی دارند بنابراین می گوییم:
data_frame.describe()
حالا اگر این کد را run کنید، توضیحاتی کلی راجع به این داده ها دریافت می کنید. این توضیحات شامل count (تعداد)، mean (میانگین)، توزیع داده ها در صدک های مختلف و انواع دیگر گزارشات آماری مربوط به داده است.
من در ابتدای جلسه گفتم که با دو data set کار می کنم تا شما روش های مختلف را ببینید. حالا اگر از داده های کشتی تایتانیک استفاده کرده باشیم چطور؟ برای استفاده از این داده ها دو راه حل دارید: یا داده ها را به صورت فایل csv دانلود کنید و یا اینکه با استفاده از ماژول urllib آن را وارد اسکریپت خود کنید. از آنجایی که روش دانلود فایل را با داده های فوتبال انجام داده ایم من روش دوم، یعنی کار با urllib، را به شما نشان می دهم. همچنین برای درک بهتر شما هر کدام از ردیف ها یا input ها را نیز در کنارش می نویسم:
In [0]: import urllib
طبیعتا شما فقط باید قسمت import urllib را در Jupyter notebook خود بنویسید و قسمت [0] In فقط نشان دهنده شماره ردیف است. با این حساب می گوییم:
In [0]: import urllib
In [0]: # دانلود داده ها از گیت هاب به سیستم خود
url = "https://raw.githubusercontent.com/GokuMohandas/practicalAI/master/data/titanic.csv"
response = urllib.request.urlopen(url)
html = response.read()
with open('titanic.csv', 'wb') as f:
f.write(html)
In [0]: # مشاهده فایل دانلود شده
!ls -l
همانطور که می بینید سه ردیف جداگانه را نوشته ام. در ردیف اول فقط ماژول urllib را وارد کرده ایم. در ردیف دوم با استفاده از ماژول urllib فایل داده را دانلود کرده ایم و سپس آن را با متد open خوانده ایم. در ردیف سوم نیز با استفاده از دستور ترمینال ls -l که فقط روی سیستم عامل های لینوکس کار می کند، از وجود فایل مطمئن شده ایم. در مرحله بعدی کتابخانه pandas را باز کرده و داده هایمان را با آن می خوانیم:
In [0]: import pandas as pd
In [0]: # data frame خواندن داده های موجود در قالب یک
df = pd.read_csv("titanic.csv", header=0)
In [0]: # نمایش پنج آیتم اولیه
df.head()
متد ()head فقط پنج آیتم اولیه را دریافت کرده و نمایش می دهد. ما از این متد استفاده می کنیم تا ستون های داده هایمان را بشناسیم و با کلیت آن ها آشنا بشویم. با اجرای کد بالا چنین نتیجه ای را می گیریم:
pclass name sex age sibsp parch ticket fare cabin embarked survived 0 1 Allen, Miss. Elisabeth Walton female 29.0000 0 0 24160 211.3375 B5 S 1 1 1 Allison, Master. Hudson Trevor male 0.9167 1 2 113781 151.5500 C22 C26 S 1 2 1 Allison, Miss. Helen Loraine female 2.0000 1 2 113781 151.5500 C22 C26 S 0 3 1 Allison, Mr. Hudson Joshua Creighton male 30.0000 1 2 113781 151.5500 C22 C26 S 0 4 1 Allison, Mrs. Hudson J C (Bessie Waldo Daniels) female 25.0000 1 2 113781 151.5500 C22 C26 S 0
ستون های ما در این داده به طور کامل مشخص است. مثلا age سن مسافر را نشان می دهد، ticket شماره بلیط مسافر را نشان می دهد، fare قیمت بلیط را نشان می دهد و الی آخر. اگر متد describe را روی داده هایمان اجرا کنیم چه می شود؟
n [0]: # دریافت نمایی از کلیت داده ها df.describe()
با اجرای این کد، نتیجه ای به شکل زیر را دریافت خواهید کرد:
pclass age sibsp parch fare survived count 1309.000000 1046.000000 1309.000000 1309.000000 1308.000000 1309.000000 mean 2.294882 29.881135 0.498854 0.385027 33.295479 0.381971 std 0.837836 14.413500 1.041658 0.865560 51.758668 0.486055 min 1.000000 0.166700 0.000000 0.000000 0.000000 0.000000 25% 2.000000 21.000000 0.000000 0.000000 7.895800 0.000000 50% 3.000000 28.000000 0.000000 0.000000 14.454200 0.000000 75% 3.000000 39.000000 1.000000 0.000000 31.275000 1.000000 max 3.000000 80.000000 8.000000 9.000000 512.329200 1.000000
این همان اطلاعات آماری است که قبلا نیز توضیح داده بودم. در مرحله بعدی می توانیم خصوصیت values را اجرا کنیم:
data_frame.values
با اجرای این دستور آرایه ای از تمام مقادیر موجود را دریافت می کنید. در واقع آرایه ای را دریافت می کنید که درون خود هر بازیکن را به صورت یک آرایه جداگانه دارد (آرایه های دو بعدی). طبیعتا از آنجایی که حجم این داده ها به شدت زیاد است، نمایش چنین آرایه ای هزاران صفحه خواهد بود و علاوه بر درگیر شدن شدید سیستم، هزاران صفحه اسکرول به ما می دهد که به طور کامل جلوی کار ما را می گیرد. Jupyter Notebook متوجه این موضوع شده و به همین خاطر تمام این داده ها را نشان نمی دهد بلکه فقط چند ردیف خاص و خلاصه شده را نمایش خواهد داد. زمانی که چنین نتیجه ای را دریافت کردید نباید نگران باشید که ممکن است کاری را اشتباه انجام داده باشید، تمام داده ها در مموری سیستم قرار دارند.
کاری که در این قسمت انجام دادیم، مرحله اول از یادگیری ماشینی، یعنی وارد کردن داده، بود. ما تا این لحظه با استفاده از کتابخانه pandas داده هایمان را به شکل یک data frame در آورده ایم.
مرحله دوم، پاک سازی داده
مرحله دوم از هوش مصنوعی پاک سازی داده بود. پاک سازی داده ها یعنی فیلتر کردن داده ها بر اساس معیار هایی خاص برای کوچک تر کردن نمونه موجود و سپس انجام عملیاتی خاص روی آن ها! به طور مثال فرض کنید که شما در یک باشگاه فوتبال کار می کنید و رئیس ما از ما می خواهد که بهترین بازیکنانی را پیدا کنیم که ارزش بازار نقل و انتقالشان از حقوق فعلی شان بیشتر باشد. ما می دانیم که در فایل csv مربوط به بازیکنان فوتبال دو ستون زیر وجود دارند:
- ستون value که به ارزش بازیکن در بازار نقل و انتقال اشاره دارد.
- ستون wage که مبلغ دریافتی فعلی بازیکن را نشان می دهد.
بررسی داده ها با تمرکز روی این دو ستون به ما این امکان را می دهد که بازیکنی با ارزش بالا را با قیمتی کمتر خریداری کنیم. برای این کار طبیعتا باید این دو ستون را از داده هایمان جدا کنیم. به این کار پاک سازی داده ها می گویند. چطور این کار را انجام بدهیم؟ کتابخانه pandas متد خاصی به نام DataFrame دارد که انجام این کار را بسیار ساده می کند:
In [0]: df1 = pd.DataFrame(data_frame, columns=['Name', 'Wage', 'Value']) df1
متد DataFrame به عنوان آرگومان اول خود یک data frame را دریافت می کند. من متغیر data_frame خودمان را به آن داده ام که حاوی تمام داده های بازیکنان فوتبالی است. آرگومان دیگر این تابع نیز آرگومانی به نام columns است که به ما اجازه می دهد ستون های خاصی را مشخص کنیم. من سه ستون نام و دستمزد و ارزش بازیکن را در قالب یک آرایه انتخاب کرده ام. در ضمن همانطور که می بینید در خط جدیدی فقط نام متغیر df1 را آورده ام و این یک اشتباه سهوی نیست. در Jupyter Notebook ها، اگر نام متغیری را بدین شکل بیاورید، مانند این است که آن را به دستور print داده باشید بنابراین محتویات داخلش را مشاهده می کنیم. در نظر داشته باشید که نام ستون ها نسبت به بزرگی و کوچکی حروف حساس هستند بنابراین حتما آن ها را به درستی بنویسید.
با اجرای کد بالا جدولی طولانی از حدود ۲۹ ردیف اول و آخر داده هایتان را دریافت می کنید که تنها همین سه ستون را دارند بنابراین مطمئن می شویم که داده هایمان محدود شده اند. مشکل اینجاست که داده هایمان در حال حاضر دارای معنی خاصی نیستند. ما باید ستون چهارمی را به این داده ها اضافه کنیم که difference (تفاوت) نام داشته باشد و تفاوت بین دستمزد و ارزش بازیکن را محاسبه کند. اضافه کردن این ستون از نظر تئوری نباید کار آنچنان پیچیده ای باشد:
In [0]: df1 = pd.DataFrame(data_frame, columns=['Name', 'Wage', 'Value']) df1['difference'] = df1['Value'] - df1['Wage'] df1
ما برای اضافه کردن یک ایندکس جدید به آرایه هایمان می توانستیم به روش بالا عمل کرده و با استفاده از ایندکس خاصی اینکار را انجام بدهیم اما اگر کد بالا را اجرا کنید خطا خواهید گرفت. به نظر شما چرا خطا می گیریم؟ مسئله اینجاست که Wage (دستمزد) و Value (ارزش بازیکن) هر دو به شکل رشته ذخیره شده اند بنابراین اجازه انجام عملیات تفریق روی رشته ها را نداریم. تبدیل این رشته ها به عدد به سادگی اضافه کردن یک متد نیست. چرا؟ به دلیل اینکه اگر به ردیف لیونل مسی نگاه کنید رشته 226.5M€ را مشاهده خواهید کرد؛ یعنی هر کدام از بازیکنان ممکن است حرف M (مخفف میلیون) یا K (مخفف کیلو یا همان هزار) را در کنار عدد خود داشته باشند. همچنین علامت واحد پول یورو نیز در کنار نامشان قرار دارد بنابراین با پاس دادن این رشته های ساده به یک تابع برای تبدلیشان به عدد کافی نیست.
با این حساب باید برای حل این مسئله یک تابع جداگانه آماده کنیم. برای اینکه کار برایتان ساده تر شود بیایید ابتدا تابعی بنویسیم که پسوندهای M و K را تبدیل به عدد می کند و سپس به سراغ علامت یورو می رویم:
def value_to_float(x):
if type(x) == float or type(x) == int:
return x
if 'K' in x:
if len(x) > 1:
return float(x.replace('K', '')) * 1000
return 1000.0
if 'M' in x:
if len(x) > 1:
return float(x.replace('M', '')) * 1000000
return 1000000.0
if 'B' in x:
return float(x.replace('B', '')) * 1000000000
return 0.0
تابع بالا سه حرف M (میلیون) و B (میلیارد) و K (هزار) را در نظر می گیرد و بر اساس آن عدد مناسب را تولید می کند. در مرحله بعدی برای حذف علامت یورو می توانیم از regex و متدی به نام replace استفاده کنیم. در نهایت شکل این قسمت از کدهایمان به شکل زیر خواهد بود:
In [0]: df1 = pd.DataFrame(data_frame, columns=['Name', 'Wage', 'Value'])
def value_to_float(x):
if type(x) == float or type(x) == int:
return x
if 'K' in x:
if len(x) > 1:
return float(x.replace('K', '')) * 1000
return 1000.0
if 'M' in x:
if len(x) > 1:
return float(x.replace('M', '')) * 1000000
return 1000000.0
if 'B' in x:
return float(x.replace('B', '')) * 1000000000
return 0.0
wage = df1['Wage'].replace('[\€,]', '', regex=True).apply(value_to_float)
value = df1['Value'].replace('[\€,]', '', regex=True).apply(value_to_float)
df1['Wage'] = wage
df1['Value'] = value
df1['difference'] = df1['Value'] - df1['Wage']
df1
ما با استفاده از replace یک regex ساده نوشته ایم که علامت € را پیدا کرده و آن را با یک رشته خالی جایگزین می کند. در این متد باید آرگومان regex=True را نیز داشته باشید تا تابع تشخیص بدهد که در حال نوشتن الگوی regex هستید. در نهایت متد apply را صدا زده ایم و نام تابع value_to_float را به آن داده ایم. این کار باعث می شود که تابع value_to_float روی نتیجه regex اجرا شود. ما این کار را برای هر دو ستون wage و value انجام داده ایم و سپس مقادیر را با مقادیر موجود در df1 جایگزین کرده ایم. حالا می توانیم ستون difference را ایجاد کنیم. با اجرای کد بالا نتیجه زیر را می گیرید:
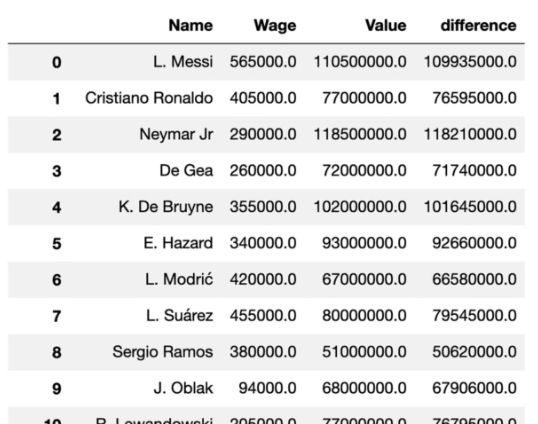
همانطور که در تصویر بالا می بینید داده های ما یک ستون جدید به نام difference دارند که تفاوت دستمزد بازیکن و ارزش بازیکن را نشان می دهد. آیا به نظر شما کارمان تمام شده است؟ قطعا خیر! در حال حاضر difference را داریم اما اگر یادتان باشد داده های ما ده ها هزار ردیف هستند و نمی توانیم آن ها را به شکل عادی مطالعه کنیم. راه حل این است که تمام داده ها را بر اساس ستون جدید difference مرتب کنیم. کتابخانه pandas متدی به نام sort_values را به ما می دهد که کارش مرتب سازی داده ها است:
In [0]: df1 = pd.DataFrame(data_frame, columns=['Name', 'Wage', 'Value'])
def value_to_float(x):
if type(x) == float or type(x) == int:
return x
if 'K' in x:
if len(x) > 1:
return float(x.replace('K', '')) * 1000
return 1000.0
if 'M' in x:
if len(x) > 1:
return float(x.replace('M', '')) * 1000000
return 1000000.0
if 'B' in x:
return float(x.replace('B', '')) * 1000000000
return 0.0
wage = df1['Wage'].replace('[\€,]', '', regex=True).apply(value_to_float)
value = df1['Value'].replace('[\€,]', '', regex=True).apply(value_to_float)
df1['Wage'] = wage
df1['Value'] = value
df1['difference'] = df1['Value'] - df1['Wage']
df1.sort_values('difference', ascending=False)
همانطور که می بینید من نام ستون difference را به sort_values داده ام و آرگومان ascending (صعودی بودن) را نیز روی False گذاشته ام تا داده ها به صورت نزولی (descending) مرتب شوند. بدین شکل بازیکنانی که بزرگترین تفاوت بین دستمزد و ارزش را دارند در ابتدا می آیند. شما می توانید کد بالا را اجرا کرده و نتایج را خودتان مشاهده کنید.

دورههای آموزشی مرتبط

مقالات مرتبط

14 شهریور 1402

23 مرداد 1402

21 مرداد 1402


آخرین سوالات کاربران
Alorazaeri در 6 سال قبل پرسیده:
Alorazaeri در 6 سال قبل پرسیده:
ما را دنبال کنید



در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.