Python حرفهای: ابزارهای یادگیری ماشینی
Professional Python: Machine Learning Tools
14 فروردین 1400

مراحل کدنویسی Machine Learning
حالا که با مباحث اولیه و مفاهیم اصلی آشنا شده ایم بهتر است شروع به کدنویسی کنیم. ممکن است تصور کنید که برای نوشتن یادگیری ماشین باید PHD داشته باشید و نابغه ای محسوب شوید اما اصلا اینطور نیست.
برای شروع کار باید با مراحل کلی کار آشنا باشید:
- وارد کردن داده درون اسکریپت: در این مرحله باید داده های خودمان را به عنوان ورودی وارد اسکریپت کنیم. ما از یک فایل CSV ساده برای این کار استفاده می کنیم.
- پاکسازی داده ها: مرحله دوم پاک کردن داده ها است. در دنیای واقعی بسیار پیش می آید که برخی از داده های ما (مثلا برخی از ستون های فایل های CSV ناقص هستند و داده ندارند). بنابراین ما این داده ها را تمیز و مرتب می کنیم تا در هنگام کار با داده ها به خطا برخورد نکنیم.
- تقسیم داده ها: مرحله سوم تقسیم کردن داده ها به بخش های مختلف است. ما برای کدنویسی یادگیری ماشین باید دو دسته داده داشته باشیم: training set و test set. دسته تمرینی یا training set داده هایی است که به عنوان ورودی به سیستم می دهیم تا خودش یاد بگیرد (مثلا ۸۰ ردیف از فایل CSV). زمانی که یادگیری انجام بشود، سیستم یک تابع را به ما برمیگرداند که می توانیم با آن دسته تست یا test set را تست کنیم تا ببینیم آیا تابع تولید شده توسط یادگیری ماشین صحیح است یا خیر.
- ساخت مدل: در هنگام ساخت مدل برای یادگیری ماشین تقریبا هیچ گاه خودمان از صفر شروع به نوشتن الگوریتم نمی کنیم بلکه همیشه از الگوریتم های نوشته شده توسط دیگران استفاده خواهیم کرد. چرا؟ به دلیل اینکه نوشتن این الگوریتم ها به دانش بالایی نیاز دارد که ما نداریم و حتی اگر دانش آن را داشته باشیم چرا باید وقت زیادی را برای این کار هدر بدهیم؟ مثال ساده این است که چرا از کتابخانه هایی مانند Flask و React و Vue و امثال آن ها استفاده نکنیم و خودمان همه چیز را از صفر بنویسیم؟
- بررسی خروجی: مرحله آخر این است که خروجی دریافتی را بررسی کنیم و ببینیم آیا test set ما دقیقا همان چیزی را به ما داده است که می خواستیم؟
- ارتقاء: در بسیاری از مواقع نتیجه دریافت شده چیزی نیست که ما به دنبالش هستیم و دارای نقص های کوچکی است. برای حل این مشکل معمولا یا داده های ورودی را بیشتر می کنیم (مثلا تعداد ستون های فایل CSV را بیشتر می کنیم) یا اینکه الگوریتم استفاده شده را تغییر می دهیم چرا که شاید آن الگوریتم مناسب کار ما نبوده باشد.
شرکت بزرگ فیسبوک در یک پست در سال ۲۰۱۸ نحوه استفاده از یادگیری ماشین در وب سایت خودشان را توضیح دادند. تصویر زیر تمام این پست را به صورت خلاصه توضیح می دهد:
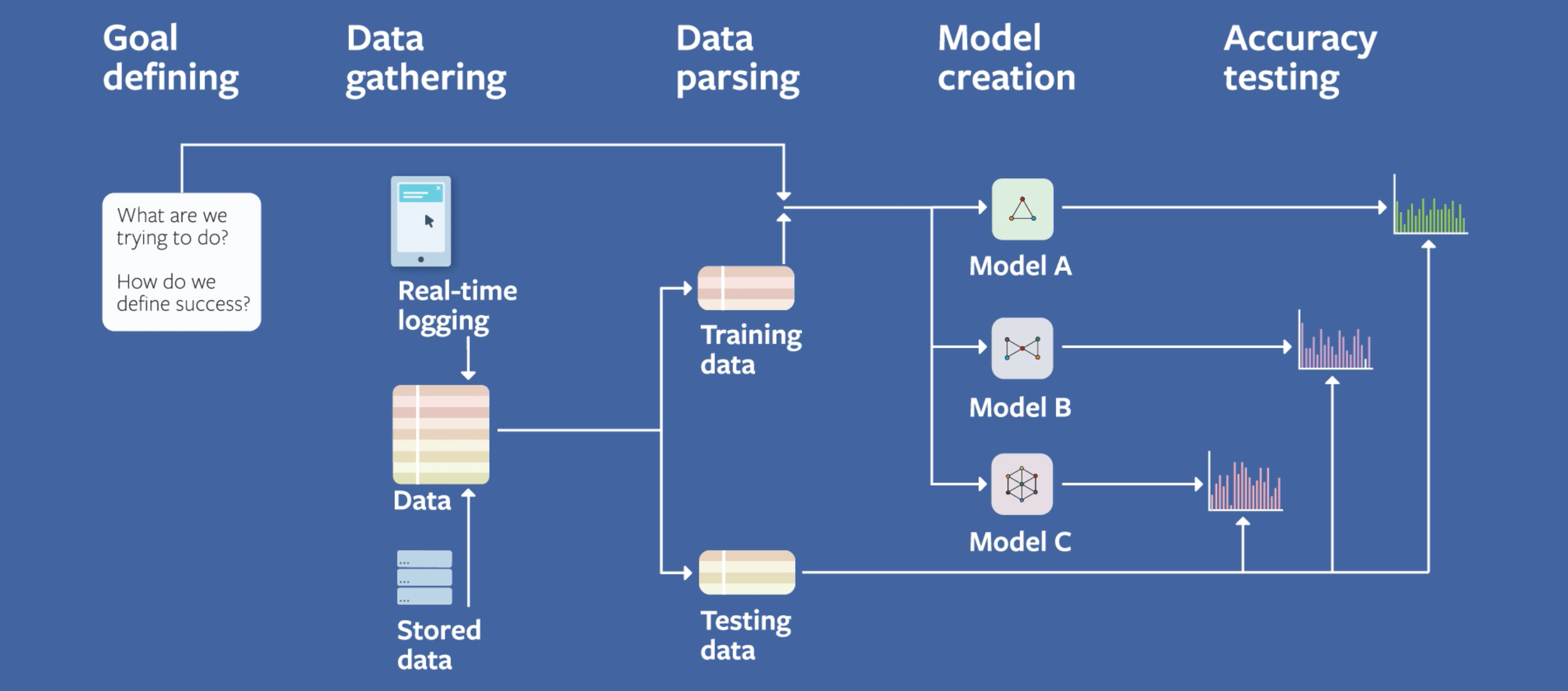
همانطور که می بینید این تصویر نیز همان مراحل ما را نشان می دهد. بیایید آن را بررسی کنیم. در مرحله اول باید هدف خودمان را تعریف کنیم، یعنی موفقیت از نظر ما چیست؟ در مرحله بعد باید داده هایمان را جمع آوری کنیم. فیسبوک این کار را از دو طریق انجام می دهد: log کردن داده ها در لحظه و استفاده از داده های ذخیره شده در پایگاه داده. مرحله بعدی تجزیه این داده ها به دو گروه training set و test set است که در موردش توضیح داده ایم و نهایتا مدل های مختلف یا الگوریتم های مختلف را امتحان می کنیم و نتیجه های تولید شده را بررسی می کنیم. هر مدلی که داده های مورد نظر ما را تولید کند، مدل مد نظر ما خواهد بود.
شاید بتوان گفت که برای ما سخت ترین مرحله جمع آوری داده ها باشد چرا که اصلا داده ای نداریم! من و شما داده های فیسبوک را نداریم بنابراین چه کار کنیم؟ ما به داده های زیادی نیاز داریم تا یادگیری ماشین بتواند فرآیند یادگیری اش را با دقت بالایی انجام بدهد. از طرفی نمی توانیم از داده های جعلی استفاده کنیم چرا که معمولا تفاوت واضحی بین داده های جعلی و داده های دنیای واقعی وجود دارد بنابراین باید به دنبال داده های معتبر و خوب و زیاد باشیم! معمولا یادگیری ماشین توسط کمپانی هایی مانند گوگل و فیسبوک مدیریت می شود چرا که دیگران به اندازه آن ها داده ندارند. بنابراین راه حل چیست؟
ابزارهای لازم برای Machine Learning
همانطور که در بخش های قبلی توضیح دادم برای پیاده سازی یادگیری ماشین باید ابزار مناسبی داشته باشیم (الگوریتم و مدل، داده های اولیه و الی آخر). زبان پایتون بزرگترین و معروف ترین زبان برای انجام یادگیری ماشین است چرا که جامعه بزرگی دارد بنابراین ماژول ها و کتابخانه های بسیار زیادی در این زمینه خواهد داشت. طبیعتا می توان با زبان های دیگر نیز یادگیری ماشین را پیاده سازی کرد اما پایتون بهترین ابزارها را دارد بنابراین رقابت با آن بسیار سخت است.
اولین ابزاری که به آن نیازی داریم کتابخانه NumPy است. با استفاده از این کتابخانه می توانیم از آرایه های چند بعدی و ماتریس های بزرگ استفاده کنیم و در عین حال عملیات های ریاضی پیچیده ای را نیز روی این داده ها انجام بدهیم. ابزار بعدی ما کتابخانه Pandas است که یک کتابخانه بسیار قدرتمند برای data analysis (تحلیل داده) محسوب می شود. اگر با فایل های اکسل و CSV در پایتون کار کرده باشید احتمالا نام Pandas را شنیده اید چرا که در این زمینه استفاده های زیادی دارد. pandas با استفاده از روش خاصی داده ها را تبدیل به ردیف و ستون می کند و به ما اجازه می دهد انواع و اقسام تکنیک های دستکاری داده و تحلیل داده را روی آن ها انجام بدهیم.
ابزار سوم ما کتابخانه مشهور scikit-learn است. این کتابخانه همان مرحله چهارم یا ساخت مدل است. ما این کتابخانه را وارد اسکریپت خود می کنیم و سپس از انواع الگوریتم های موجود در آن (classification یا regression و غیره) استفاده می کنیم. ابزار چهارم ما کتابخانه matplotlib می باشد. این کتابخانه یک charting library است، یعنی مسئول تولید گراف و چارت های مختلف بر اساس داده های ما است. این کتابخانه به ما اجازه می دهد که داده ها را visualize (بصری سازی) کنیم. ابزار بعدی ما Jupyter Notebooks است. اگر ما بخواهیم داده ها را در ویرایشگر هایی مانند PyCharm یا Visual Studio Code بنویسیم کارمان کمی سخت می شود. Jupyter Notebooks به ما اجازه می دهد که داده هایمان را مرحله به مرحله زیر نظر بگیریم و حتی در هر مرحله visualize کنیم.
آخرین ابزاری که به آن نیاز داریم همان داده های ورودی است! به نظر شما از کجا می توانیم داده های معتبر پیدا کنیم؟ وب سایت kaggle مجموعه ای از متخصصان یادگیری ماشین است که Jupyter Notebook های خود را با دیگران به اشتراک می گذارند و با هم مسابقاتی را برگزار می کنند و dataset هایشان را نیز در این سایت قرار داده اند. به طور مثال اگر به صفحه www.kaggle.com/datasets بروید لیست بسیار بزرگی از داده های مختلف را پیدا خواهید کرد. بعضی از این داده ها رسمی و مهم هستند (مانند جرایم اتفاق افتاده در شهر بوستون آمریکا) و بعضی از این داده ها کمی شوخ طبعی دارند (به طور مثال تمام توهین های آقای ترامپ در توییتر). این داده ها واقعی و معتبر هستند و معمولا حجم بسیار زیادی دارند. به طور مثال جرایم شهر بوستون حدود ۵۰ تا ۹۰ مگابایت داده است (صد ها هزار ردیف).
نصب Jupyter Notebooks
برای نصب Jupyter Notebooks پیشنهاد می شود از ابزاری به نام Anaconda استفاده کنیم. این ابزار یک پلتفرم علوم داده است که به ما اجازه می دهد از انواع و اقسام ابزارهای مختلف مانند Jupyter Notebooks به صورت یکجا استفاده کنیم. مزیت استفاده از Anaconda این است که ابزارهای مختلف مانند NumPy و Jupyter Notebooks و Pandas و matplotlib و امثال آن ها را به صورت یکجا به ما می دهد که باعث آسان تر شدن کار ما خواهد شد.
برای نصب Anaconda باید به صفحه دانلود Anaconda بروید و از آنجا روی سیستم عامل مورد نظر خودتان کلیک کنید. ممکن است از شما پرسیده شود که نسخه نصب شده پایتون شما چیست؟ طبیعتا شما پایتون ۳ را انتخاب می کنید و شروع به دانلود خواهید کرد. توجه داشته باشید که Anaconda با تمام ابزارهای مورد نیاز تحلیل داده و یادگیری ماشین می آید بنابراین حجم زیادی دارد (حدود ۵۰۰ مگابایت) و نصب آن کمی طول خواهد کشید.
نصب Anocanda برای کاربران ویندوز
کاربران ویندوز: پس از دانلود فایل نصبی که حدود ۵۰۰ مگابایت حجم دارد باید آن را اجرا کنید تا مراحل نصب شروع شود. این مراحل مانند نصب نرم افزارهای ساده هستند بنابراین پیچیدگی خاصی ندارند. تنها نکته اینجاست که اگر گزینه Add Anaconda to my PATH environment variable را مشاهد کردید، تیک آن را غیر فعال کنید. چرا؟ به دلیل اینکه ما پایتون را در سیستم خودمان نصب کرده ایم و در PATH ما وجود دارد بنابراین نیازی به اضافه کردن Anaconda به آن نداریم چرا که ممکن است باعث ایجاد مشکلاتی شود.
نصب Anocanda برای کاربران لینوکس
کاربران لینوکس: با دانلود فایل نصبی (پسوند sh) کار دانلود تمام می شود اما باید آن را نصب کنیم. برای این کار ترمینال را در محل فایل دانلود شده باز کرده و نامش را به صورت اسکریپت اجرا کنید:
amir@HP:~/Downloads$ ./Anaconda3-2020.11-Linux-x86_64.sh
طبیعتا بسته به زمانی که این مقاله را می خوانید ممکن است که نام این فایل برای شما متفاوت باشد. همچنین مطمئن باشید که permission های اجرایی (execute) را برای این فایل لحاظ کرده اید تا بتواند اجرا شود. با اجرای دستور بالا چنین نتیجه ای را می بینید:
Welcome to Anaconda3 2020.11 In order to continue the installation process, please review the license agreement. Please, press ENTER to continue >>>
کلید Enter را بزنید و به انتهای توافق نامه اسکرول کنید. در آنجا چنین سوالی را می بینید:
Do you accept the license terms? [yes|no]
در این قسمت عبارت yes را تایپ کرده و enter بزنید. سپس از شما چنین سوالی پرسیده می شود:
Anaconda3 will now be installed into this location: /home/amir/anaconda3 - Press ENTER to confirm the location - Press CTRL-C to abort the installation - Or specify a different location below
من با مسیر پیش فرض نصب مشکلی ندارم بنابراین بدون تغییر دادن آن کلید Enter را می زنم. حالا فرآیند نصب شروع می شود که کمی طولانی خواهد بود. پس از اتمام آن از شما پرسیده می شود:
Preparing transaction: done Executing transaction: done installation finished. Do you wish the installer to initialize Anaconda3 by running conda init? [yes|no]
من در اینجا yes را نوشته و enter می زنم. در مرحله بعدی ممکن است نوشته هایی مانند نوشته های زیر را دریافت کنید:
==> For changes to take effect, close and re-open your current shell. <== If you'd prefer that conda's base environment not be activated on startup, set the auto_activate_base parameter to false: conda config --set auto_activate_base false Thank you for installing Anaconda3! =========================================================================== Working with Python and Jupyter notebooks is a breeze with PyCharm Pro, designed to be used with Anaconda. Download now and have the best data tools at your fingertips. PyCharm Pro for Anaconda is available at: https://www.anaconda.com/pycharm
ما با این نوشته ها کاری نداریم. فقط یادتان باشد که ترمینال خود را ببندید. حالا دوباره ترمینال را باز کرده و دستور زیر را در آن اجرا کنید:
conda info
با اجرای این دستور باید نتیجه زیر را بگیرید:
active environment : base active env location : /home/amir/anaconda3 shell level : 1 user config file : /home/amir/.condarc populated config files : conda version : 4.9.2 conda-build version : 3.20.5 python version : 3.8.5.final.0 virtual packages : __glibc=2.32=0 __unix=0=0 __archspec=1=x86_64 base environment : /home/amir/anaconda3 (writable) channel URLs : https://repo.anaconda.com/pkgs/main/linux-64 https://repo.anaconda.com/pkgs/main/noarch https://repo.anaconda.com/pkgs/r/linux-64 https://repo.anaconda.com/pkgs/r/noarch package cache : /home/amir/anaconda3/pkgs /home/amir/.conda/pkgs envs directories : /home/amir/anaconda3/envs /home/amir/.conda/envs platform : linux-64 user-agent : conda/4.9.2 requests/2.24.0 CPython/3.8.5 Linux/5.8.0-43-generic ubuntu/20.10 glibc/2.32 UID:GID : 1000:1000 netrc file : None offline mode : False
اگر به جای گزارش بالا، خطا دریافت کنید یعنی مراحل نصب به درستی انجام نشده است.
همیشه پیشنهاد می شود که پس از نصب Anaconda ابزارهای آن را به روز رسانی کنیم، بنابراین در مرحله بعدی دستور زیر را در ترمینال اجرا کنید:
conda update conda
اگر از شما سوالی پرسیده شد y را تایپ کرده و enter بزنید. با این کار ابزار conda را به روز رسانی می کنیم. پس از اتمام این عملیات حالا دستور زیر را در ترمینال اجرا کنید:
conda update anaconda
باز هم حرف y را تایپ کرده و enter بزنید تا به روز رسانی ها نصب شوند. طبیعتا در هر دو مرحله بالا باید به اینترنت متصل باشید. در نهایت دستور زیر را اجرا کنید:
anaconda-navigator
با انجام این کار رابط گرافیکی Anaconda نیز برایتان نصب می شود و می توانید از منوی برنامه هایتان آن را پیدا کنید.
پیکربندی Anocanda برای کاربران ویندوز و لینوکس
پس از نصب شدن Anaconda باید آن را پیکربندی کنیم تا بتوانیم از ابزارهایی که می خواهیم استفاده کنیم. انجام این کار برای کاربران ویندوز و لینوکس یکی می باشد. اگر از کاربران ویندوز باشید باید به دنبال برنامه ای به نام Anaconda Navigator باشید تا رابط گرافیکی Anaconda برایتان باز شود اما اگر از کاربران لینوکس هستید باید از anaconda-navigator استفاده کنید تا رابط گرافیکی آن را اجرا کنید. با باز کردن رابط گرافیکی برنامه های مختلفی که به آن ها دسترسی دارید را مشاهده خواهید کرد. یکی از این برنامه ها Jupyter Notebooks است بنابراین روی آن کلیک کنید تا در مرورگر برایتان باز شود. ظاهر Jupyter Notebooks به شکل زیر است:
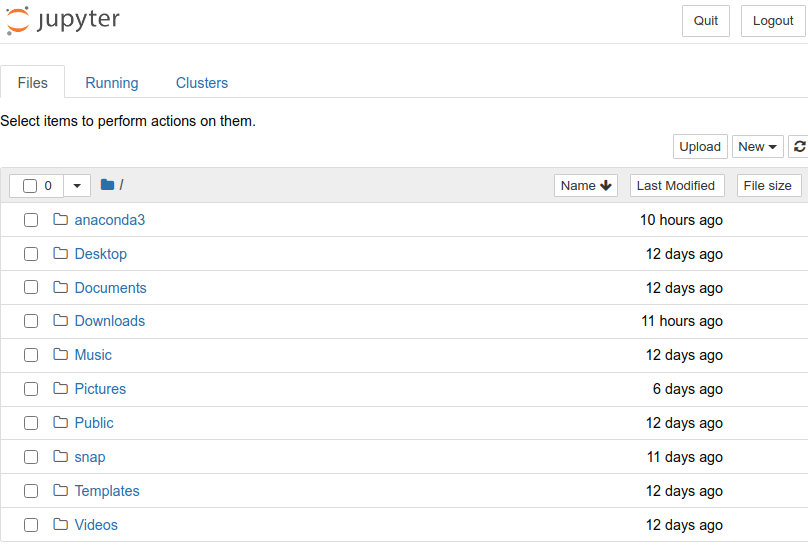
طبیعتا ممکن است که نام فایل ها و پوشه ها برای شما فرق کند اما کلیت ظاهر آن به همین شکل است. این صفحه در آدرس http://localhost:8888/tree برایتان باز می شود که یعنی به صورت محلی اجرا شده است بنابراین از دیدن آدرس آن تعجب نکنید. در سمت راست و بالای صفحه (در تصویر بالا مشخص است) گزینه ای به نام upload وجود دارد که کنارش گزینه دیگری به نام new را دارد. روی New کلیک کرده و سپس گزینه Python 3 را انتخاب کنید. با این کار یک notebook جدید را می سازیم اما در نظر داشته باشید که در هر مسیری باشید، notebook جدید در آن مسیر ساخته خواهد شد بنابراین به مسیر صحیح بروید و سپس روی آن کلیک کنید. با این کار صفحه جدیدی به شکل زیر برایتان باز خواهد شد:
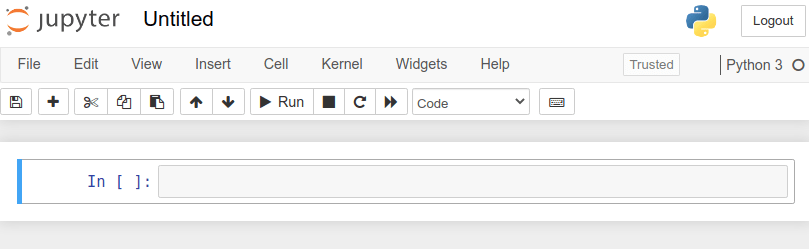
از تصویر بالا مشخص است که بالای صفحه نام notebook ما را نمایش می دهد. این نام به صورت پیش فرض Untitled است. شما باید روی این نام کلیک کرده و نام دلخواه خود را وارد کنید. این نام می تواند هر مقداری باشد؛ من از وب سایت Kaggle یک دست داده دلخواه را انتخاب می کنم. مثلا بازیکنان فیفا در سال ۲۰۱۹:
بنابراین نام Jupyter Notebook خود را FIFA انتخاب کرده ام. با کلیک روی این لینک به صفحه آن در Kaggle منتقل می شوید و می توانید از آنجا dataset مربوط به را دانلود کنید. البته از شما خواسته می شود که با حساب گوگل خود sign in شوید. فایلی که از Kaggle دانلود می کنید به صورت فشرده شده (zip) است بنابراین باید ابتدا آن را از حالت فشرده استخراج کنید. در مرحله بعدی باید فایل استخراج شده (یک فایل CSV است) را به محلی ببرید که Notebook خود را در آن ایجاد کرده اید.
حالا دوباره به FIFA (همان notebook تازه ساخته شده) برگردید و در خط اول کتابخانه pandas را وارد کنید. حالا می توانیم فایل CSV را بخوانیم:
import pandas as pd
pd.read_csv('data.csv')
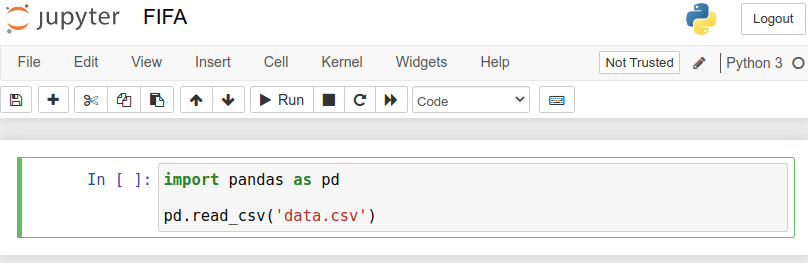
پس از نوشتن این کد باید روی دکمه Run کلیک کنید. با انجام این کار داده ها برایتان خوانده شده و در یک جدول نمایش داده می شود. داده هایی که برایتان نمایش داده شده است یک data frame است. کتابخانه pandas فایل های CSV را به شکلی می خواند که ساختار خاصی به نام data frame تولید کند و سپس به ما اجازه می دهد این ساختار خاص را دستکاری کنیم.
نکته: در برخی از مواقع سرور به صورت خودکار ریستارت می شود اما دچار مشکلاتی خواهد بود بنابراین ممکن است خطا دریافت کنید. در این حالت یک بار سرور را از ترمینال خود قطع کرده (Ctrl + C) و دوباره flask run را اجرا کنید.
اگر بخواهیم اطلاعاتی کلی راجع به data frame خود داشته باشیم می توانیم کد زیر را در notebook خود اجرا کنیم:
import pandas as pd
data_frame = pd.read_csv('data.csv')
data_frame.shape
با اجرای این کد نتیجه زیر را می گیریم:
(18208, 89)
یعنی داده های ما ۸۹ ستون و ۱۸۲۰۸ ردیف هستند که حجم عظیمی از داده می باشد!

دورههای آموزشی مرتبط

مقالات مرتبط

14 شهریور 1402

23 مرداد 1402

21 مرداد 1402


آخرین سوالات کاربران
Alorazaeri در 6 سال قبل پرسیده:
Alorazaeri در 6 سال قبل پرسیده:
ما را دنبال کنید



در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.