مبانی ثانویهی پایتون - انواع آرگومان
Professional Python: Types of Function Arguments
16 اسفند 1399

آرگومان های بی نهایت!
قبلا با مبحث argument و keyword argument آشنا شدیم و می دانیم که آرگومان چیست اما روش خاصی برای استفاده از آن ها وجود دارد که بسیار مهم است. فرض کنید ما تابعی داریم که چندین عدد را گرفته و سپس جمع آن ها را به ما می دهد:
def super_func(number): return sum(number) super_func(1,2,3,4,5)
تابع sum یکی از توابع پیش فرض پایتون است بنابراین نیازی به تعریف آن نداریم. این تابع چندین عدد را گرفته و مجموع آن ها را برمی گرداند. با اجرای این کد خطای زیر را دریافت می کنیم:
Traceback (most recent call last): File "./prog.py", line 3, in <module> TypeError: super_func() takes 1 positional argument but 5 were given
یعنی تابع super_func یک آرگومان موقعیتی می گیرد اما ما ۵ آرگومان را به آن پاس داده ایم! طبیعتا انتظار چنین چیزی را نیز داشتیم چرا که ما فقط یک پارامتر به نام number را در تعریف تابع تعریف کرده ایم. در زبان پایتون اگر بخواهیم به تابعی بگوییم که می تواند هر تعداد آرگومان را دریافت کند باید از علامت ستاره (*) استفاده کنیم:
def super_func(*numbers): return sum(numbers) print(super_func(1,2,3,4,5))
با اجرای کد بالا نتیجه ۱۵ را می گیریم که جمع تمامی این اعداد است! ما به همین راحتی توانسته ایم تابعی بنویسیم که هر تعداد آرگومانی را دریافت می کند. برای درک بهتر می توانیم numbers را چاپ کنیم:
def super_func(*numbers): print(numbers) return sum(numbers) print(super_func(1,2,3,4,5))
با اجرای کد بالا نتیجه زیر را می گیریم:
(1, 2, 3, 4, 5) 15
با این حساب آرگومان های ما در قالب یک tuple قرار گرفته اند. البته قرارداد اینطور است که نام چنین پارامترهایی را args بگذارید:
def super_func(*args): return sum(args) print(super_func(1,2,3,4,5))
همانطور که گفتم پیروی از قراردادها الزامی نیست اما به شدت پیشنهاد می شود. از آنجایی که بیشتر توسعه دهندگان پایتون از این قراردادها پیروی می کنند بهتر است در همین ابتدای کار آن ها را یاد گرفته و شما نیز شروع به استفاده از آن ها کنید.
این بحث متعلق به آرگومان های موقعیتی بود اما اگر آرگومان های کلیدواژه ای داشتیم چطور؟ در چنین حالتی به جای یک علامت ستاره از دو علامت ستاره (**) استفاده می کنیم:
def super_func(*args, **kwargs): print(args) print(kwargs) print(super_func(1,2,3,4,5, number1=123, number2=88))
برخلاف آرگومان های موقعیتی که در یک tuple ذخیره می شوند، آرگومان های کلیدواژه ای در دیکشنری ها ذخیره می شوند. با اجرای کد بالا نتیجه زیر را می گیریم:
(1, 2, 3, 4, 5)
{'number1': 123, 'number2': 88}
None
خط اول یک tuple است که مربوط به اولین دستور print ما است (args) خط دوم یک دیکشنری بوده و متعلق به دستور print دوم ما است (kwargs) و در نهایت none را داریم که مربوط به print آخر (فراخوانی تابع) می باشد چرا که فعلا تابع ما هیچ چیزی برنمی گرداند. در ضمن نام گذاری kwargs (مخفف keyword arguments) بدین شکل از قراردادهای زبان پایتون است.
حالا برای جمع زدن این مقادیر باید چه کار کنیم؟ مسئله اینجاست که kwargs یک دیکشنری است بنابراین دارای کلید و مقدار است و نمی توانیم آن را مستقیما به sum پاس بدهیم. سعی کنید خودتان کمی به این سوال فکر کرده و سپس به جواب من نگاه کنید.
def super_func(*args, **kwargs): total = 0 for items in kwargs.values(): total += items return sum(args) + total print(super_func(1,2,3,4,5, number1=123, number2=88))
ما در ابتدا متغیری به نام total تعریف کرده ایم که در ابتدا صفر است، سپس با حلقه ای روی تمام مقادیر kwargs گردش کرده و آن ها را به total اضافه کرده ایم. نهایتا جمع تمام این آرگومان ها برابر با total به علاوه جمع آرگومان های موقعیتی است. اگر این کد را اجرا کنید نتیجه ۲۲۶ را دریافت می کنیم.
در نهایت باید به نکته ای خاص توجه کنید. در هنگام نوشتن پارامتر برای یک تابع باید از قانون خاصی تبعیت کنید که ترتیب نوشتن پارامترها را مشخص می کند:
parameters, *args, default parameters, **kwargs
- parameters یعنی پارامترهای موقعیتی و معمولی
- args* را در همین جلسه توضیح دادیم.
- default parameters: پارامترهایی هستند که مقدار پیش فرض دارند (در جلسات قبل توضیح دادیم)
- kwargs** را در همین جلسه توضیح دادیم.
بگذارید در عمل به شما نشان بدهم که منظورم چیست. به تابع زیر نگاه کنید:
def super_func(name, *args, job='developer', **kwargs):
# کار هایی که این تابع انجام می دهد
pass
print(super_func('Amir', 12, 'roxo', someparam='myparam'))
name یک پارامتر ساده و موقعیتی است و در فراخوانی آن معادل Amir است. سپس args* را داریم که معادل 12 و roxo هستند. پارامتر سوم مقدار پیش فرض developer را دارد و من با آن مشکلی ندارم بنابراین اصلا آن را پاس نداده ام تا همان مقدار پیش فرض ثبت شود. نهایتا نیز یک پارامتر کلیدواژه ای داریم که مقدار myparam را به خود اختصاص داده است. از آنجایی که نمی خواستم کار خاصی را انجام بدهم فقط دستور pass را به تابع داده ام که با مشکل مواجه نشویم. در حال حاضر اگر کد بالا را اجرا کنید مقدار none را می گیرید که مربوط به دستور print است.
تمرین: پیدا کردن بزرگترین عدد زوج
حتما متوجه شده اید که در طول این دوره چندین تمرین به شما داده شده است. من از شما می خواهم که این تمرین ها را خودتان و بدون نگاه کردن به پاسخ من پیدا کنید تا یادگیری شما بهتر شود. در این قسمت نیز مثل همیشه می خواهیم کمی روی مهارت هایمان کار کنیم اما این بار صورت سوال متفاوت است: تابعی را تعریف کنید که به عنوان آرگومان خود یک لیست را گرفته و سپس بزرگترین عدد زوج از بین اعداد درون این لیست را پیدا کند. ابتدا خوب به این موضوع فکر کنید و سعی کنید خودتان جواب بدهید. در نهایت جواب خود را با جواب من مقایسه کنید.
def highest_even(some_list): even_numbers = [] for item in some_list: if item % 2 == 0: even_numbers.append(item) return max(even_numbers) print(highest_even([1,2,3,4,5,77,8,99,13]))
در تعریف این تابع دو مرحله اصلی را داریم. مرحله اول فیلتر اعداد زوج و مرحله دوم پیدا کردن بزرگ ترین عدد از بین این اعداد است. برای فیلتر کردن اعداد زوج باید ابتدا متغیری به نام even_numbers را تعریف کنیم. سپس بین اعداد لیست پاس داده شده گردش می کنیم و اگر باقی مانده تقسیم هر عدد از این اعداد بر ۲ برابر با صفر بود یعنی عدد زوج است بنابراین آن عدد را با متد append به لیست اعداد زوج اضافه می کنیم. در نهایت زمانی که این حلقه تمام شد از تابع max برای پیدا کردن بزرگ ترین عدد استفاده می کنیم و نتیجه را برمی گردانیم. حالا هر لیستی را که به این تابع بدهید بزرگ ترین مقدارش را برایتان برمی گرداند.
یادتان باشد که روش های مختلفی برای حل یک مشکل وجود دارد بنابراین ممکن است پاسخ شما با پاسخ من متفاوت باشد. مهم این است که به پاسخ دقیق برسید و البته کدهایتان بیش از حد شلوغ و ناخوانا نباشند.
اپراتور walrus
یکی از قابلیت های جدید در زبان پایتون اپراتور walrus است. walrus یک حیوان است که در فارسی به آن «گراز دریایی» می گوییم. می توانید با جست و جوی تصویر این حیوان در گوگل متوجه شباهت آن با این اپراتور شوید. این اپراتور به شکل =: نوشته می شود و برای انتساب مقادیر به یک متغیر در expression ها کاربرد دارد. به مثال زیر توجه کنید:
my_string = "This is my string"
if (len(my_string) > 10):
print(f'This string is too long; It has {len(my_string)} characters')
اگر این رشته بیشتر از ۱۰ کاراکتر داشته باشد ما رشته ای را چاپ می کنیم که می گوید رشته پاس داده شده بیش از حد طولانی بوده و X کاراکتر دارد به طوری که X تعداد کاراکترهای این رشته باشد. با اجرای کد بالا نتیجه زیر را می گیریم:
This string is too long; It has 17 characters
بنابراین کدها بدون مشکل اجرا می شوند اما کدهایی که در این قسمت نوشته ایم بهترین شکل ممکن را ندارد. چرا؟ اگر یادتان باشد یکی از ویژگی های کد خوب DRY (تکرار نکردن کدها) بود اما ما در این کد دو بار از (my_string)len استفاده کرده ایم یا به عبارتی طول رشته را بی جهت ۲ بار حساب کرده ایم! اگر کد ما طولانی تر بود قطعا دچار تکرار بیشتر کدها نیز می شدیم. در چنین حالتی اپراتور walrus به کمک ما می آید و به ما اجازه می دهد مقدار محاسبه شده را درون یک متغیر قرار بدهیم:
my_string = "This is my string"
if ((n := len(my_string)) > 10):
print(f'This string is too long; It has {n} characters')
با این کار مقدار (my_string)len در متغیری به نام n قرار می گیرد بنابراین باید آن را درون یک پرانتز بگذاریم تا نتیجه کل آن (تعداد کاراکترها) با عدد ۱۰ مقایسه شود. از این به بعد متغیر n در دسترس ما خواهد بود بنابراین می توانیم در {n} از آن استفاده کنیم. با اجرای این کد نتیجه زیر را می گیریم:
This string is too long; It has 17 characters
مبحث scope
یکی از مباحث بسیار مهم در هر زبان برنامه نویسی scope متغیرها و مقادیر در آن است. scope سطحی از کد را مشخص می کند که ما در آن به متغیرها و مقادیر خاصی دسترسی داریم. به زبان ساده تر scope مشخص می کند که آیا می توانیم به متغیر X یا Y دسترسی داشته باشیم یا خیر. زبان پایتون functional scope دارد. آیا می دانید معنی آن چیست؟ فرض کنید ما کد زیر را داشته باشیم:
global_scope = 10
من در اینجا متغیری به نام global_scope را دارم که عدد ۱۰ را به آن داده ام. از آنجایی که این متغیر در بلوک کد خاصی تعریف نشده است می گوییم که این متغیر دامنه سراسری یا global scope دارد. به عبارت دیگر می توانیم از «سراسر» این فایل به آن دسترسی داشته باشیم. مثال:
global_scope = 10 def print_global_scope(): print(global_scope) print_global_scope()
با اجرای کد بالا عدد ۱۰ را می گیریم و مشکلی وجود ندارد اما اگر متغیری را درون بلوک کد خاصی تعریف کنیم چطور؟ به مثال زیر توجه کنید:
def set_my_variable(): global_scope = 10 set_my_variable() print(global_scope)
تابع set_my_variable تنها متغیری به نام global_scope را تعریف می کند بنابراین من آن را صدا زده ام و سپس global_scope را چاپ کرده ام. به نظر شما با اجرای کد بالا چه اتفاقی می افتد؟
Traceback (most recent call last): File "main.py", line 12, in <module> print(global_scope) NameError: name 'global_scope' is not defined
همانطور که می بینید یک خطا دریافت کرده ایم که می گوید global_scope تعریف نشده است. چرا؟ متغیر global_scope درون یک تابع تعریف شده است بنابراین دامنه دسترسی آن فقط در همین تابع می باشد و پس از پایان اجرای تابع از بین می رود. زبان های برنامه نویسی مختلف scope های مختلفی را دارند اما همانطور که گفتم در پایتون functional scope داریم که یعنی function ها (توابع) scope خودشان را دارند. با این حساب هر چیزی که درون یک تابع تعریف شود functional scope دارد و هر چیزی که خارج از توابع تعریف شود global scope خواهد داشت. اگر با زبان های برنامه نویسی دیگر مثل جاوا اسکریپت کار کرده باشید احتمالا به وجود چندین scope دیگر عادت کرده اید اما مبحث scope در پایتون بسیار ساده است و فقط دو حالت «سراسری» و «تابع» را دارد.
نکته: global scope یا دامنه سراسری در مقابل local scope یا دامنه محلی قرار دارد. منظور از دامنه محلی این است که متغیر فقط در «محل» تعریف خودش قابل دسترسی است (درون تابع). بنابراین اگر در طول این دوره از عبارت scope محلی یا دامنه محلی استفاده کردم باید بدانید که منظور من همان functional scope است. این دو نام در زبان پایتون یکی هستند.
حالا که با مفهوم scope آشنا شده اید سعی کنید به این سوال جواب بدهید: به نظر شما با اجرای کد زیر چه مقداری را دریافت می کنیم؟
a = 1 def confusion(): a = 5 return a print(a) print(confusion())
ما در این کد دو دستور print را داریم. در خط اول متغیری با دامنه سراسری (global scope) داریم که مقدار ۱ را دارد. سپس تابعی را تعریف کرده ایم که آن هم متغیری به نام a و با مقدار ۵ را دارد اما این متغیر درون تابع تعریف شده است بنابراین دامنه تابع را دارد. با این حساب دستور اول print به متغیر خط اول اشاره می کند و نتیجه ۱ را برمی گرداند در حالی که دستور دوم print تابع را اجرا کرده و متغیر a درونِ آن تابع صدا زده می شود بنابراین عدد ۵ را دریافت می کنیم. در این کد می بینیم که دو متغیر a کاملا از هم جدا هستند و باعث تغییر مقدار یکدیگر نشده اند. چرا؟ به دلیل اینکه مفسر پایتون برای بررسی متغیرها به ترتیب زیر عمل می کند:
- بررسی با دامنه محلی (local scope) شروع می شود.
- در صورتی که چیزی در دامنه محلی نباشد به سراغ پدرِ دامنه محلی می رویم.
- در مرحله بعدی به بررسی دامنه سراسری (global scope) می پردازیم.
- در نهایت بررسی را در کدهای خود زبان پایتون انجام می دهیم.
بگذارید برایتان توضیح بدهم. در مثال بالا پدرِ دامنه محلی، همان دامنه سراسری است اما ممکن است دو تابع تو در تو داشته باشیم و در چنین حالتی پدرِ دامنه محلیِ تابع داخلی، برابر با دامنه محلی تابع خارجی می شود. مثال:
a = 1 def parent(): a = 10 def confusion(): return a return confusion() print(a) print(parent())
با اجرای کد بالا نتیجه 1 و 10 را می گیریم. چطور؟ ما تابع parent را صدا زده ایم که a را برابر ۱۰ قرار داده است. همچنین در همین تابع، تابع دیگری به نام confusion داریم تعریف شده و صدا زده شده و نهایتا برگردانده می شود. زمانی که parent را صدا زده ایم، تابع confusion نیز تعریف و اجرا می شود اما confusion درون خودش متغیری به نام a را برمی گرداند. مفسر پایتون ابتدا درون scope محلی (درون تابع confusion) را بررسی می کند تا a را پیدا کند اما چنین چیزی نداریم بنابراین حالا به scope یا دامنه پدرِ confusion (یعنی تابع parent) رفته و به دنبال a می گردیم. خوشبختانه a در آن جا برابر ۱۰ بوده و پیدا می شود بنابراین آن را برمی گردانیم. در صورتی که متغیر a درون تابع parent نیز نبود به سراغ global scope می رفتیم و در صورتی که در global scope نیز نبود به سراغ کدهای خود پایتون می رفتیم و اگر آنجا هم نبود یک خطا برگردانده می شد. منظور من از «کدهای زبان پایتون» توابع و مقادیری است که به صورت پیش فرض در پایتون تعریف شده اند. به طور مثال صدا زدن تابع print از این مسئله پیروی کرده و در آخرین مرحله (بررسی کدهای زبان پایتون) پیدا می شود.
یادتان باشد که پارامترها نیز دارای دامنه محلی هستند:
def my_function(param1):
print(param1)
my_function("AM")
با اجرای این دستور AM چاپ می شود بنابراین می دانیم که param1 دامنه محلی و متعلق به تابع دارد.
کلیدواژه global
در برخی اوقات درون تابع خود قرار داریم اما می خواهیم به متغیری سراسری اشاره کنیم. به نظر شما در چنین حالتی راه حل چیست؟ کد زیر یک نمونه از چنین موقعیتی است:
counter = 0 def some_function(): counter += 1 return counter print(some_function())
counter به معنی شمارنده است و ما می خواهیم در این قسمت کاری کنیم که تابع some_function متغیر counter را یک واحد افزایش دهد اما counter در دامنه سراسری تعریف شده است و اضافه کردن آن درون تابع some_function باعث خطا خواهد شد چرا که درون این تابع به دامنه سراسری دسترسی نداریم. به نظر شما چطور می توانیم این مشکل را حل کنیم؟ شاید بگویید که می توانیم متغیر counter را درون این تابع تعریف کنیم اما چنین کاری باعث دو مشکل می شود؛ مشکل اول اینجاست که اگر متغیر را درون تابع تعریف کنیم دیگر در دامنه سراسری به آن دسترسی نداریم. مشکل دوم این است که با این کار دیگر یک شمارنده نخواهیم داشت:
def some_function(): counter = 0 counter += 1 return counter print(some_function()) print(some_function()) print(some_function()) print(some_function())
با اجرای این کد نتیجه زیر را می گیریم:
1 1 1 1
چرا؟ به دلیل اینکه شمارنده ما در هر بار اجرای تابع دوباره روی صفر قرار می گیرد و یک واحد به آن اضافه می شود بنابراین همیشه عدد یک را دریافت می کنیم. ساده ترین راه برای حل این مشکل استفاده از دستور global است:
counter = 0 def some_function(): global counter counter += 1 return counter print(some_function()) print(some_function()) print(some_function()) print(some_function()) print(counter)
همانطور که می بینید برای انجام این کار ابتدا باید global counter را اجرا کنیم تا به مفسر پایتون بگوییم که قصد دسترسی به متغیری با دامنه سراسری به نام counter را داریم. سپس در خط بعدی می توانیم به آن دسترسی داشته باشیم و آن را یک واحد افزایش دهیم. با اجرای کد بالا نتیجه زیر را می گیریم:
1 2 3 4 4
همانطور که می بینید شمارنده ما هر بار یک واحد افزایش پیدا کرده است. آخرین عدد چاپ شده (۴) متعلق به دستور print برای متغیر counter است تا ثابت کنیم که این متغیر در حال حاضر روی 4 قرار دارد. این مثال فقط برای این بود که شما نحوه استفاده از دستور global را درک کنید اما معمولا توصیه می شود که از آن استفاده نکنید. چرا؟ به دلیل اینکه ما با انجام این کار دامنه های سراسری و محلی را در هم ادغام کرده و همه چیز را برای خودمان پیچیده می کنیم.
راه بهتر و استاندارد تر انجام این کار، استفاده از dependency injection (تزریق وابستگی) است. مبحث dependency injection طولانی و مفصل است اما ما می توانیم یک نمونه بسیار ساده از آن را در همین متد بررسی کنیم:
counter = 0 def some_function(counter): counter += 1 return counter print(some_function(some_function(some_function(counter)))) print(counter)
زمانی که some_function اجرا می شود شمارنده را گرفته و پس از افزایش آن، آن را برمی گرداند. با توجه به این مسئله می توانیم some_function را به صورت تو در تو صدا بزنیم تا هر تابع مقدار counter را بگیرد و آن را یک واحد افزایش بدهد. با اجرای این کد نتیجه زیر را می گیریم:
3 0
همانطور که می بینید متغیر سراسری counter دست نخورده است و مقدار صفر را دارد اما متغیر محلی counter که به صورت آرگومان پاس داده می شود واحد به واحد افزایش پیدا کرده است و حالا عدد ۳ را به ما می دهد.
چرا به Scope نیاز داریم؟
شاید با خودتان بگویید چرا همه متغیرها و مقادیر در پایتون را به صورت سراسری نداریم؟ چرا به scope های مختلف محلی و سراسری نیاز داریم؟ مسئله اینجاست که اگر scope ها را حذف کنیم کارمان به عنوان توسعه دهنده راحت تر می شود اما هزینه هایمان بیشتر خواهد شد! یعنی چه؟ به کد زیر توجه کنید:
def name_function(): name = "Amir" occupation = "Developer" workplace = "Roxo"
اگر چنین تابعی را اجرا کنیم، سه متغیر جدید را ساخته ایم که یعنی سه محل از مموری سیستم خود را اشغال کرده ایم. به عبارتی ما فقط در چهار خط، سه محل از مموری سیستم را گرفته ایم. شاید در نگاه اول این موضوع آنچنان بد به نظر نرسد اما اگر در یک برنامه بزرگ باشیم تعداد متغیرها بسیار زیاد خواهد شد و به همین دلیل مموری مصرف شده توسط برنامه ما بسیار بالا خواهد رفت.
در زمانی که scope های مختلفی را داریم چطور؟ در چنین حالتی زمانی که اجرای تابع name_function تمام شود، مفسر پایتون تمام متغیرهای تعریف شده در آن را حذف می کند بنابراین مموری ما خالی می شود تا در دسترس سیستم قرار بگیرد (به این مسئله garbage collection می گوییم). اگر scope وجود نداشت، تمام متغیرهای تعریف شده در کل اسکریپت تا انتهای اجرای اسکریپت فعال باقی می ماندند و باعث اصراف مموری می شدند و همانطور که می دانید اضافه کردن CPU و مموری به یک سرور کار آنچنان ارزانی نیست. دلیل وجود scope این است!
نصب پایتون به صورت محلی
ما تا این بخش کدهای خودمان را درون وب سایت هایی مانند repl.it یا w3schools.com و امثال آن ها می نوشتیم اما از این به بعد می خواهیم کدهای پیشرفته تری بنویسیم بنابراین باید یک محیط توسعه را روی سیستم خودمان ایجاد کنیم. من توضیحات مربوط به سیستم عامل های لینوکس و ویندوز را برای نصب پایتون در اختیار شما قرار می دهم بنابراین باید بر اساس سیستم عامل خودتان، مرحله به مرحله با من پیش بیایید.
نصب پایتون برای کاربران ویندوز
برای نصب پایتون روی ویندوز باید به وب سایت رسمی پایتون بروید (www.python.org) و سپس روی لینک downloads و سپس windows کلیک کنید. با انجام این کار به صفحه https://www.python.org/downloads/windows منتقل می شوید. در این صفحه دو نسخه مختلف از پایتون را مشاهده می کنید: نسخه اول نسخه جدید (پایتون ۳) و نسخه دوم پایتون قدیمی (نسخه ۲) است. در زمان نگارش این مقاله آخرین نسخه پایتون ۳.۹ می باشد اما در زمانی که شما این مقاله را می خوانید ممکن است نسخه های جدید تری را نیز داشته باشیم. همانطور که در ابتدای این دوره توضیح دادم، پایتون ۲ به زودی منسوخ خواهد شد بنابراین حتما روی گزینه دانلود برای پایتون ۳ کلیک کنید:
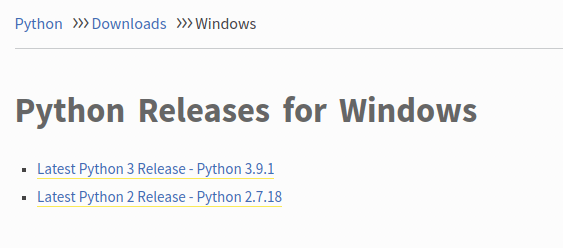
با کلیک روی پایتون ۳ به صفحه دیگری منتقل می شوید که مخصوص آن نسخه خاص از پایتون است. به انتهای آن صفحه اسکرول کنید تا به جدولی شبیه به جدول زیر برسید:

این جدول انواع و اقسام روش های مختلف نصب پایتون را به شما نشان می دهد (نصب با کامپایل کردن سورس کد، نصب با installer و غیره). آسان ترین روش که روش پیشنهاد شده توسط تیم توسعه پایتون نیز می باشد استفاده از installer است. در تصویر بالا می بینید که گزینه ای به نام Windows installer (64-bit) در انتهای این جدول قرار دارد و روبروی آن عبارت recommended نوشته شده است. ما روی این لینک کلیک می کنیم تا فایل نصبی پایتون دانلود شود. عبارت ۶۴ یعنی این فایل روی سیستم های ۶۴ بیتی نصب می شود. در صورتی که ویندوز شما ۳۲ بیتی می باشد می توانید از لینک Windows installer (32-bit) استفاده کنید (تفاوتی ندارند). با کلیک روی هر کدام از این لینک ها فرآیند دانلود آغاز می شود. پس از دانلود روی فایل نصبی کلیک کرده و آن را باز کنید:
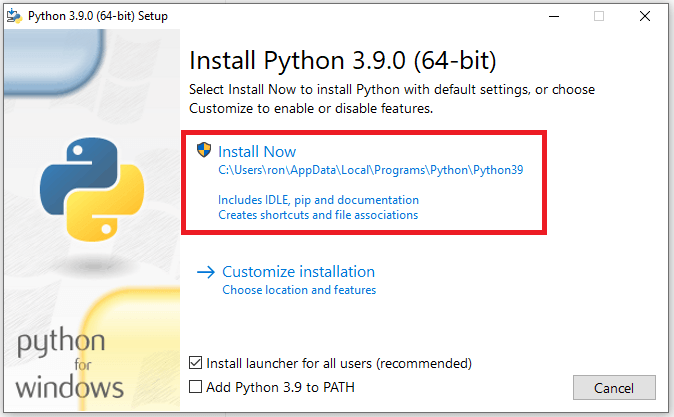
این قسمت بسیار مهم است؛ حتما تیک گزینه Add Python 3.9 to PATH را فعال کنید. در تصویر بالا مشاهده می کنید که این گزینه در پایین پنجره قرار داشته و فعال نیست اما شما باید آن را فعال کنید. با این کار پایتون به PATH ویندوز اضافه شده و به ما اجازه می دهد که از تریق command prompt با زبان پایتون کار کنیم. پس از فعال کردن این قسمت روی گزینه Install Now کلیک کنید که با مستطیل قرمز رنگ مشخص شده است.
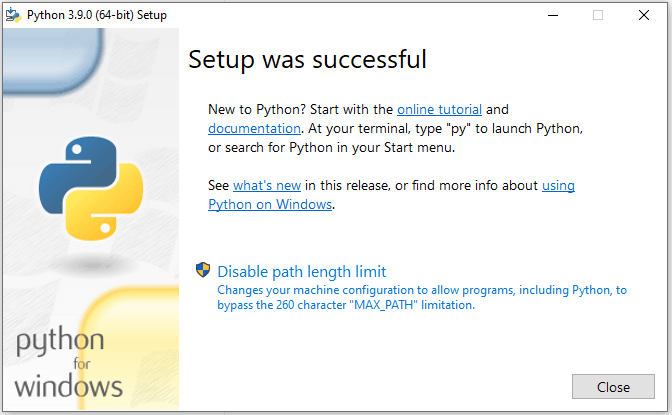
زمانی که فرآیند نصب تمام شود چنین تصویری را مشاهده می کنید. در این قسمت می توانید روی دکمه close کلیک کنید تا برنامه بسته شود. حالا اگر command prompt ویندوز را باز کرده و عبارت python را در آن وارد کنید، نتیجه ای مثل نتیجه زیر را دریافت می کنید:
Python 3.9.1 (default, Dec 7 2020, 09:36:53) [GCC 10.2.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>>
اگر چنین نتیجه ای را دریافت کردید یعنی پایتون برایتان نصب شده است.
اگر از ویندوز ۱۰ استفاده می کنید یعنی به PowerShell دسترسی دارید. در چنین حالتی من پیشنهاد می کنم به جای command prompt (همان CMD) از PowerShell استفاده کنید چرا که علاوه بر دستورات عادی می توانید دستورات لینوکس را نیز در آن اجرا کنید و به طور کل رابط قدرتمند تری از CMD است. ممکن است برخی از دستوراتی که در این دوره برایتان توضیح خواهم داد در CMD کار نکنند به همین جهت است که PowerShell را پیشنهاد می کنم. در صورتی که ویندوز ۱۰ ندارید، پیشنهاد می کنم GitBash را دانلود کرده و نصب کنید.
نصب پایتون برای کاربران لینوکس
اگر از کاربران لینوکس باشید به احتمال زیاد پایتون به صورت پیش فرض برایتان نصب شده است و نیازی به انجام کار خاصی ندارید. برای اطمینان از این موضوع باید یکی از دو دستور زیر را در ترمینال سیستم خود اجرا کنید:
python3 --version python --version
در سیستم های لینوکس پایتون با نام python3 یا python یا python2 نصب شده است به همین دلیل است که می گویم هر دو دستور بالا را اجرا کنید تا مطمئن شوید. در صورتی که با اجرای یکی از این دستورات نتیجه ای مانند نتیجه زیر را گرفتید (نسخه پایتون به شما نمایش داده شد) یعنی پایتون روی سیستم شما نصب شده است:
Python 3.8.6
اما در صورتی که با نتیجه ای گرفتید که به شما می گوید Command 'python' not found یعنی پایتون نصب نشده است. من از Ubuntu استفاده می کنم بنابراین دستور python3 برای من کار می کند اما دستوری به نام python وجود ندارد. در صورتی که پایتون برای شما نصب شده بود نیازی به مطالعه این بخش ندارید و می توانید به قسمت بعدی بروید، در غیر این صورت باید ابتدا دستور زیر را در ترمینال خود اجرا کنید:
sudo apt-get update
سپس دستور زیر را اجرا کنید:
sudo apt-get install python3.8 python3-pip
با این کار پایتون برای شما نصب می شود.
محیط توسعه
توسعه دهندگان حرفه ای از ابزار های حرفه ای استفاده می کنند. ما می دانیم که می توانیم کدهای پایتون خود را درون یک ترمینال یا PowerShell اجرا کنیم اما توسعه دهندگان حرفه ای چنین کاری را انجام نمی دهند. چرا؟ به دلیل اینکه انجام چنین کاری سخت بوده و در پروژه های بزرگ به هیچ عنوان جواب نمی دهد. بهترین گزینه های پیش روی ما Code editor ها (ویرایشگر کد) و IDE ها (محیط های توسعه یکپارچه) هستند. code editor ها نسبت به IDE ها سبک تر و سریع تر هستند اما قابلیت های خوبی ارائه می کنند، از طرف دیگر IDE ها سنگین تر هستند اما قابلیت های بسیار بسیار بیشتری را ارائه می دهند و در سطحی بسیار حرفه ای کار می کنند.
از ویرایشگر های معروف می توان به sublime و visual studio code اشاره کرد و از IDE های معروف می توان به PyCharm و SPYDER اشاره کرد. شما می توانید از هر کدام از این ویرایشگر ها استفاده کنید؛ برای دانلود آن ها کافی است نامشان را در گوگل جست و جو کرده و آن ها را دانلود و نصب کنید.
تنها نکته ای که باقی می ماند این است که اگر می خواهید از PyCharm استفاده کنید باید بدانید که PyCharm دو نسخه professional و community دارد. نسخه professional رایگان نیست چرا که چند قابلیت اضافه (پشتیبانی از HTML و جاوا اسکریپت و SQL) را نیز دارد اما ما نیازی به آن نداریم بنابراین نسخه community را دانلود کنید که رایگان نیز می باشد. از آنجایی که PyCharm یک IDE کامل است، حجم آن نسبت به visual studio code بسیار بیشتر است (حدود ۴۰۰ مگابایت) بنابراین این نکته را نیز در هنگام دانلود در نظر بگیرید.
نصب تمامی ابزار های معرفی شده در این قسمت کار تقریبا آسانی است و سختی خاصی ندارد بنابراین اگر با کامپیوتر ها در حد ساده آشنا باشید می توانید این کار را انجام بدهید. از جلسه بعدی وارد برنامه نویسی شیء گرای پایتون می شویم. من شخصا از Visual Studio Code استفاده می کنم اما شما می توانید از هر کدام از برنامه های دیگری که معرفی کردم نیز استفاده کنید.

دورههای آموزشی مرتبط

مقالات مرتبط

14 شهریور 1402

23 مرداد 1402

21 مرداد 1402


آخرین سوالات کاربران
Alorazaeri در 6 سال قبل پرسیده:
Alorazaeri در 6 سال قبل پرسیده:
ما را دنبال کنید



در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.