Python حرفهای: آشنایی با یادگیری ماشینی
Professional Python: Machine Learning
14 فروردین 1400

Machine Learning و حوزه آن
یادگیری ماشینی یا machine learning یکی از پر سر و صدا ترین مباحث سال های اخیر در حوزه برنامه نویسی بوده است اما آنقدرها که فکر می کنید نیز پیچیده نیست! ما تا این قسمت از این سری آموزشی فهمیده ایم که کامپیوترها در انجام بعضی از کارها عالی هستند اما این کارها از پیش تعریف شده هستند. یعنی اگر به کامیپوتر خود بگوییم که این تصویر را بگیر و ۱۰۰ کپی از آن بساز، کامپیوتر این کار را به راحتی انجام می دهد اما برخی اوقات به مسائلی برخورد می کنیم که از پیش تعریف شده نیستند.
به طور مثال بازی شطرنج را در نظر بگیرید. ما (در تئوری) می توانیم با استفاده از هزاران هزار دستور if به کامپیوتر بگوییم که چطور شطرنج بازی کند و بر اساس رفتار بازیکن مقابل از خودش واکنش نشان بدهد اما این کار بسیار زمان بر خواهد بود. بیایید شطرنج را نیز قبول کنیم چرا که بالاخره دارای قوانین از پیش تعریف شده است و حداقل از نظر تئوری می توانیم یک بازی شطرنج را با زبان پایتون و به شکل عادی بنویسیم اما اگر بخواهیم از کامپیوتر خود بپرسیم «گربه چیست؟» چه جوابی به ما می دهد؟ آیا می توانیم به شکل عادی کدی در زبان پایتون بنویسیم که با دریافت تصاویر مختلف، بتواند گربه ها را در آن تشخیص بدهد؟ شما می توانید به کامپیوتر بگویید که یک گربه، دم دارد و کوچک است و دو چشم دارد و گوش های مثلثی دارد و الی آخر اما این توصیفات کافی نیستند. چرا؟ مثلا اگر به کامپیوتر بگوییم گربه «میو میو» می کند کامپیوتر از شما می پرسد میو میو چیست؟ گوش چیست؟ مثلث چیست؟ در ضمن هر گربه ای رنگ خاص خودش را دارد و اگر گربه ای گوش راستش را از دست داده باشد چطور؟ هر تصویر از زاویه مختلفی گرفته می شود بنابراین بی نهایت زاویه داریم و توصیف این چیز ها در عمل تقریبا غیر ممکن می شود. با این حساب آیا ساده تر نیست که به کامپیوتر بگوییم این مسائل را خودش یاد بگیرد؟
زمانی که صحبت به یادگیری ماشین می شود باید به گراف زیر توجه داشته باشید تا جایگاه آن را در مقایسه با دیگر تکنولوژی های مربوط ببینید:
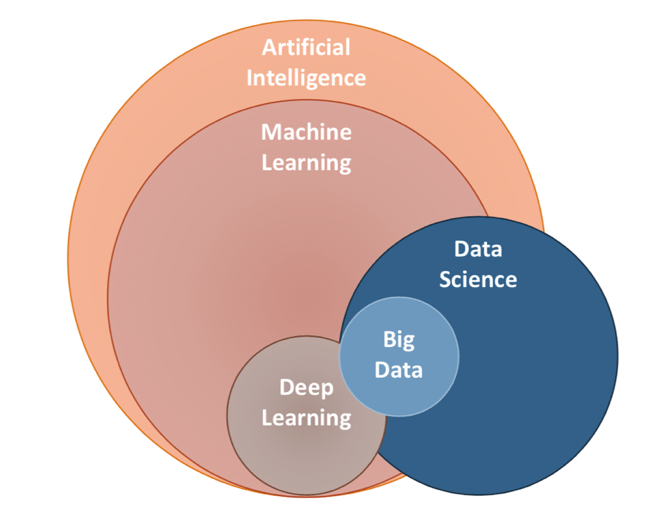
حوزه بزرگ و مرجع اصلی AI یا Artificial Intelligence (هوش مصنوعی) است. هوش مصنوعی همانطور که از نامش مشخص است هوشی است که از سمت یک ماشین مصنوع (ساخته شده) نمایش داده می شود. ما از نظر تئوری سه نوع هوش مصنوعی را داریم:
- Narrow AI: این هوش مصنوعی narrow (باریک یا محدود) است چرا که روی یک کار خاص تمرکز کرده و با دیگر مسائل کاری ندارد. این نوع هوش مصنوعی می تواند برای اهداف خاصی مانند تشخیص بیماری ریوی از روی عکس MRI و امثال آن مورد استفاده قرار بگیرد. مثال هایی از استفاده از این تکنولوژی Cortana در ویندوز ۱۰ یا facial recognition (تشخیص چهره) می باشد. نام دیگر این نوع هوش مصنوعی Artificial narrow intelligence است.
- General AI: هوش مصنوعی general یا عمومی، دانش را از یک دامنه گرفته و به دامنه های دیگر انتقال می دهد. این نوع هوش مصنوعی در سطح هوش انسان قرار می گیرد. نام دیگر این نوع هوش مصنوعی Artificial general intelligence است.
- Super AI: این نوع هوش مصنوعی از انسان ها هوشمند تر و سریع تر خواهد بود. نام دیگر این نوع هوش مصنوعی Artificial superintelligence است.
در حال حاضر ما فقط توانسته ایم به Narrow AI دست پیدا کنیم و هنوز General AI یا Super AI وجود ندارد اما در حال کار برای دستیابی به آن ها هستیم.
با این حساب یادگیری ماشین فقط یک زیرمجموعه از مبحث بزرگ AI است. هدف اصلی یادگیری ماشین، دسترسی به هوش مصنوعی با استفاده از تشخیص الگوهای تکراری بین داده های مختلف است. در تصویر بالا مبحث deep learning را نیز می بینید؛ deep learning فقط یکی از روش های مختلف برای پیاده سازی یادگیری ماشین است. در عین حال مبحثی به نام data science یا علوم داده را داریم. کار اصلی علوم داده این است که از داده های غیر ساختار یافته، الگوهای معنی دار یا داده های با ارزش را پیدا کند. احتمالا شما هم متوجه شده اید که data science و machine learning بسیار به هم نزدیک هستند و در اکثر آگهی های شغلی نیز تفاوتی بین این دو قائل نمی شوند! به همین دلیل در قسمت های آینده در مورد هر دوی این مباحث صحبت خواهیم کرد چرا که نمی توانیم بدون صحبت از علوم داده از یادگیری ماشین صحبت کنیم.
Machine Learning چطور کار می کند؟
کامپیوترها به زبان ما انسان ها صحبت نمی کنند. به طور مثال اگر تصویر ماری را به کامپیوتر خود نشان بدهید و بگویید «آیا این تصویر یک مار است؟» کامپیوتر جوابی برای شما ندارد. ما به عنوان انسان، زمانی که به تصویر یک مار در هر شرایطی (چه در یک فیلم، چه در یک کارتون، چه در نقاشی، چه در یک تصویر در کنار حیوانات دیگر و الی آخر) نگاه می کنیم می توانیم آن را تشخیص بدهیم. مشکل اینجاست که کامپیوترها زبان ما را نمی فهمند بنابراین نمی توانیم به کامپیوتر به زبان خودمان یاد بدهیم که مار چیست. مثلا اگر به کامپیوتر بگوییم مار دست و پا ندارید کمکی نکرده ایم چرا که ماشین و هواپیما نیز دست و پا ندارند!
در برنامه نویسی رویه ای و عادی، ما به عنوان برنامه نویس، ورودی و دستورالعمل های قابل اجرا روی آن ورودی را مشخص می کنیم و کار کامپیوتر این است که این بر اساس این دستورالعمل ها، ورودی را پردازش کرده و نتیجه را به ما بدهد. در یادگیری ماشینی از ما خواسته می شود که ورودی را به سیستم بدهیم اما به جای ارائه دستورالعمل برای انجام پردازش های خاص، پاسخِ پردازش را به سیستم می دهیم. در این حالت کسی که دستورالعمل را مشخص می کند، خود برنامه است! به طور مثال ما نمی توانیم به کامپیوتر بگوییم «مار» چه شکلی است و چطور آن را تشخیص بدهد بنابراین به سیستم می گوییم که خودت یاد بگیر مار چه شکلی دارد! چطور این کار را می کنیم؟ همانطور که گفتم ورودی های مختلفی را به سیستم می دهیم (مثلا ۲۰۰۰ عکس مار) و پاسخ پردازش (تشخیص مار) را نیز می دهیم.
Machine Learning و تاریخچه داده
معمولا نیازهای دنیای تکنولوژی همگی از حوزه کسب و کار شروع می شوند. در ابتدای اختراع کامپیوترها داده های کمی وجود داشت و ما آن ها را در فایل های ساده ای ذخیره می کردیم. تصور کنید که ما یک فروشگاه ساده را داریم و تمام خرید و فروش های خود را در فایل های اکسل ثبت و نگهداری می کنیم. انسان ها می توانند این داده های کوچک را به راحتی بخوانند و مسائل ساده را پیش بینی کنند. به طور مثال اگر شرکت ما هر سال در ماه اسفند شاهد فروش بالاتری بوده است، ساده است که بگوییم احتمالا امسال نیز فروش بالایی در اسفند خواهیم داشت. چرا؟ حدس می زنیم که دلیل فروش بالا به خاطر عید نوروز باشد.
با بزرگ تر شدن کامپیوترها وارد دنیای پایگاه های داده رابطه ای شدیم. حالا کسب و کارها داده های بسیار زیادی دارند بنابراین دیگر نمی توانیم از فایل های اکسل استفاده کنیم و به همین دلیل است که به سراغ پایگاه های داده رابطه ای رفته ایم. پایگاه های داده رابطه ای با استفاده از زبانی به نام SQL به ما کمک می کردند که مدیریت و نظم دهی به داده هایمان را سریع تر و بهینه تر کنیم اما مکانیسم تحلیلی آن ها هنوز هم مانند فایل های اکسل بود و برای تحلیل این داده ها معمولا آن ها را دریافت کرده و تحلیل می کردیم. طبیعتا استفاده از این پایگاه های داده بسیار راحت تر بود و سود بیشتری نصیب شرکت ها می کرد.
سپس در سال های ۲۰۰۰ تا ۲۰۱۰ مفهوم تازه ای به نام Big Data معرفی شد. در این دهه ها حجم داده ها آنچنان زیاد شد که دیگر ذخیره سازی آن ها در فایل های اکسل غیرممکن بود. تصور کنید تعداد لایک های روی فیسبوک و ذخیره کردن آن ها چه حجم عظیمی از داده را خواهد داشت! مسئله اینجاست که پایگاه های داده رابطه ای دارای ساختاری از پیش تعیین شده بودند (schema) اما هیچکس نمی تواند به جرات بگوید که این حجم عظیم از داده ها همیشه دارای ساختار یکسانی خواهند بود. اگر حجم داده های ما اینقدر عظیم باشد احتمال زیادی وجود دارد که داده های ما به صورت ۱۰۰% ساختار یافته نخواهند بود.
این حجم از داده حتما در آینده افزایش پیدا خواهد کرد بنابراین هر روز بیشتر به سمت machine learning حرکت می کنیم. حجم داده ها در آینده آنچنان افزایش پیدا می کند که ممکن نیست بتوانیم مانند فایل های اکسل به آن ها نگاه کنیم. منظور من از ممکن نیست، مفید نبودن انجام چنین کاری است. مثلا اگر یک میلیارد ردیف از تاریخچه خرید کاربران داشته باشیم، آیا عاقلانه است که به صورت دستی به این داده ها نگاه کنیم؟ با پاس دادن این داده ها به یادگیری ماشین، کسب و کارمان بهتر از همیشه خواهد بود. چرا؟ به دلیل اینکه ماشین ها در تحلیل این داده ها بسیار بهتر از ما انسان ها هستند. یادگیری ماشینی در اصل به دلیل رشد و حجم عظیم داده ها و پیشرفت های سخت افزاری به وجود آمد.
سه دسته بندی برای Machine Learning
ما می توانیم یادگیری ماشین را به سه قسمت تقسیم کنیم.
Supervised: یادگیریِ supervised یعنی یادگیری با نظارت! تصور کنید یک دانش آموز و در حال یادگیری ریاضی هستید. در این کلاس معلم بر شما نظارت دارد تا مطمئن باشد شما درس را به درستی یاد گرفته اید. یادگیری ماشینی نظارت شده یا supervised نیز به همین شکل است. یعنی یک سری داده را داریم (مثلا ۱۰۰۰ تصویر از سیب و ۱۰۰۰ تصویر از گلابی) و این داده ها را label زده ایم، یعنی مشخص کرده ایم که کدام تصاویر، تصاویر سیب و کدام تصاویر، تصاویر گلابی هستند. حالا داده ها را به همراه جواب به برنامه می دهیم تا با استفاده از این نمونه یاد بگیرد. در این حالت نتیجه بر اساس روشی که خودمان به ماشین یاد داده ایم تولید می شود.
Unsupervised: یادگیریِ unsupervised یعنی یادگیری بدون نظارت! ما همیشه داده های آماده شده و label شده را نداریم بنابراین در این حالت داده های خام را مستقیما به الگوریتم می دهیم. در این حالت الگوریتم ما با دسته بندی داده ها و مقایسه آن ها سعی می کند نقاط مشترک و متفاوت را پیدا کند و خودش با داده ها آشنا شود. به طور مثال با استفاده از رفتار یک مشتری، سعی می کنیم که کالاهای مورد علاقه او را حدس زده و به او پیشنهاد بدهیم. در این حالت نتیجه بر اساس چیزی که خود ماشین تشخیص داده است تولید می شود.
Reinforced: یادگیری تقویت شده یا reinforced نوعی الگوریتم است که در آن ماشین یاد می گیرد خودش با محیط اطراف تعامل کند. به طور مثال یک برنامه را طوری طراحی می کنیم که یک بازی را ببرد. در این حالت برنامه ما آنقدر با محیط تعامل می کند و بازی را بازی می کند تا بتواند مرحله را کامل کند. یک مثال ساده از این دست، ماشین های خودران و جاروبرقی های هوشمند هستند که خودشان خانه شما را می شناسند و به مرور مسیرهای خانه را یاد می گیرند. در این نوع یادگیری ماشین هیچ چیزی نمی داند بلکه شروع به امتحان و خطا می کند و هر بار که پاسخ مثبتی گرفت به همان مسیر ادامه می دهد.
یادتان باشد که هدف در supervised machine learning محاسبه یا پیش بینی خروجی است در حالی که در unsupervised machine learning شناسایی الگو های مخفی و در reinforced machine learning یادگیری یک سری عملیات خاص است.

دورههای آموزشی مرتبط

مقالات مرتبط

14 شهریور 1402

23 مرداد 1402

21 مرداد 1402


آخرین سوالات کاربران
Alorazaeri در 6 سال قبل پرسیده:
Alorazaeri در 6 سال قبل پرسیده:
ما را دنبال کنید



در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.