Python حرفهای: بصریسازی دادهها
Professional Python: Data Visualization
14 فروردین 1400

کار با Matplotlib
ما در جلسه قبل موفق شدیم که داده هایمان را به نوعی مرتب و تمیز کنیم که آماده استفاده باشد. این کار با کد زیر انجام شد:
In [0]: df1 = pd.DataFrame(data_frame, columns=['Name', 'Wage', 'Value'])
def value_to_float(x):
if type(x) == float or type(x) == int:
return x
if 'K' in x:
if len(x) > 1:
return float(x.replace('K', '')) * 1000
return 1000.0
if 'M' in x:
if len(x) > 1:
return float(x.replace('M', '')) * 1000000
return 1000000.0
if 'B' in x:
return float(x.replace('B', '')) * 1000000000
return 0.0
wage = df1['Wage'].replace('[\€,]', '', regex=True).apply(value_to_float)
value = df1['Value'].replace('[\€,]', '', regex=True).apply(value_to_float)
df1['Wage'] = wage
df1['Value'] = value
df1['difference'] = df1['Value'] - df1['Wage']
df1.sort_values('difference', ascending=False)
من در جلسه قبل نحوه کار این کد را توضیح دادم بنابراین اگر فراموش کرده اید باید به آن جلسه برگردید. با اجرای این کد روی داده های خودمان چنین نتیجه ای را می گیریم:
Name Wage Value difference 2 Neymar Jr 290000.0 118500000.0 118210000.0 0 L. Messi 565000.0 110500000.0 109935000.0 4 K. De Bruyne 355000.0 102000000.0 101645000.0 5 E. Hazard 340000.0 93000000.0 92660000.0 15 P. Dybala 205000.0 89000000.0 88795000.0 ... ... ... ... ... 17752 S. Phillips 1000.0 0.0 -1000.0 12192 H. Sulaimani 3000.0 0.0 -3000.0 3550 S. Nakamura 4000.0 0.0 -4000.0 4228 B. Nivet 5000.0 0.0 -5000.0 864 Hilton 18000.0 0.0 -18000.0 18208 rows × 4 columns
در حال حاضر خواندن داده هایی که داریم برای افراد عادی کمی سخت است چرا که با اعداد بسیار بزرگ سر و کار داریم. کار ما به عنوان تحلیل گر داده این است که داده ها را استخراج کرده و مرتب کنیم اما زمانی که نوبت به ارائه این داده ها برسد، باید در نظر داشته باشید که دیگران تحلیل گر داده نیستند بنابراین اعداد و ارقام بزرگ برایشان خسته کننده است و ارزش کار شما، آنچنان که باید، نمایش داده نمی شود.
در صورتی که از Jupyter Notebook ها استفاده می کنید باید به خاطر داشته باشید که هر کدام از In ها (input ها یا خانه های جداگانه) کاملا مستقل از هم هستند بنابراین زمانی که Jupyter Notebook خود را ریستارت کنید (مثلا سیستم خود را خاموش کرده اید و روز بعد دوباره به سراغ پروژه آمده اید) دیگر به خانه های قبلی دسترسی ندارید. برای شروع باید روی تک تک این خانه ها کلیک کرده و گزینه run را انتخاب کنید تا هر خانه یا input جداگانه اجرا شود. با این کار داده های ما در مموری سیستم قرار می گیرند و می توانیم کد های خودمان را در ادامه اجرا کنیم.
در اصل بهتر بود که روشی برای نمایش بصری این داده ها داشته باشیم. در جلسه قبل برایتان توضیح دادم که کتابخانه بسیار بزرگی به نام Matplotlib وجود دارد که برای بصری سازی داده ها استفاده می شود. مسئله اینجاست که این کتابخانه بسیار حرفه ای است و برای یادگیری آن نیاز به گذراندن دوره ای جداگانه خواهیم داشت. همچنین نیاز به آشنایی با انواع نمودار ها و مباحث آماری مانند داده های پیوسته و داده های رسته ای را خواهیم داشت. طبیعتا ما در این دوره کلی که در مورد تمام زبان پایتون است نمی توانیم از چنین چیزی استفاده کنیم و تمام دستورات را توضیح بدهیم.
راه حل بهتر استفاده از کتابخانه ای به نام Seaborn است. این کتابخانه روی کتابخانه Matplotlib سوار می شود و استفاده از آن را برای ما ساده تر می کند. چطور؟ این کتابخانه یک API سطح بالاتر از Matplotlib ارائه می دهد که درک Matplotlib را برایمان ساده تر می کند. طبیعتا هنوز هم در حوزه علوم داده و ترسیم نمودار هستیم بنابراین Seaborn هنوز هم نیاز به دوره جداگانه خودش را دارد چرا که قابلیت های بسیار زیادی دارد اما آنقدر ساده و قابل فهم می باشد که بخواهیم به صورت خلاصه و سریع از آن استفاده کنیم.
من برای شروع کدنویسی به input سوم خودم می روم. برای یادآوری می گویم که اولین import ما این کد بود:
import pandas as pd
data_frame = pd.read_csv('data.csv', dtype='unicode')
data_frame.shape
دومین input ما بدین شکل بود:
df1 = pd.DataFrame(data_frame, columns=['Name', 'Wage', 'Value'])
def value_to_float(x):
if type(x) == float or type(x) == int:
return x
if 'K' in x:
if len(x) > 1:
return float(x.replace('K', '')) * 1000
return 1000.0
if 'M' in x:
if len(x) > 1:
return float(x.replace('M', '')) * 1000000
return 1000000.0
if 'B' in x:
return float(x.replace('B', '')) * 1000000000
return 0.0
wage = df1['Wage'].replace('[\€,]', '', regex=True).apply(value_to_float)
value = df1['Value'].replace('[\€,]', '', regex=True).apply(value_to_float)
df1['Wage'] = wage
df1['Value'] = value
df1['difference'] = df1['Value'] - df1['Wage']
df1.sort_values('difference', ascending=False)
و حالا می خواهیم وارد سومین input بشویم. جدا کردن input ها از هم باعث می شود یک فاصله منطقی بین کد های موجود داشته باشید. این مسئله درک کد ها را بسیار ساده تر می کند اما از نظر عملکرد و نتیجه هیچ تفاوتی ندارد که تمام کد ها را درون یک input بنویسید یا آن را به صد input تقسیم کنید. در ابتدا باید seaborn را وارد Jupyter Notebook خود کنیم بنابراین:
import seaborn as sns sns.set()
متد set در seaborn باعث تنظیم ظاهر نمودار های تولید شده خواهد شد. زمانی که هیچ پارامتری را به آن پاس ندهیم، از تم پیش فرض seaborn استفاده خواهد شد که تم مناسبی است. اگر می خواهید با این گزینه بیشتر آشنا شوید به documentation رسمی کتابخانه seaborn مراجعه کنید. در مرحله بعدی باید محور های x و y نمودار خود را مشخص کنیم بنابراین:
import seaborn as sns sns.set() graph = sns.scatterplot(x='Wage', y='Value', data=df1) graph
در این مرحله متغیری به نام graph را ایجاد کرده ایم که حاوی نمودار ما خواهد بود. در این بخش باید انتخاب کنیم که چه نموداری مناسب داده های ما است. من برای این داده ها از نمودار scatterplot یا همان «نمودار نقطه ای» استفاده کرده ام چرا که در نمایش پراکندگی بسیار خوب عمل می کند. در این نوع نمودار باید محور x و y را مشخص کنید که من به ترتیب wage (دستمزد بازیکن) و value (ارزش بازیکن) را به عنوان این محورها انتخاب کرده ام. نهایتا نیز باید data یا همان DataFrame مورد نظرتان را مشخص کنید که برای ما df1 است. اگر شما نام DataFrame خود را چیزی غیر از df1 گذاشته اید باید همان نام را پاس بدهید. اگر یادتان باشد گفتم که با نوشتن نام متغیر در Jupyter Notebook ها، مقدارش نمایش داده می شود بنابراین در انتهای کد بالا متغیر graph را نیز یک بار ذکر کرده ام تا نمودار را مشاهده کنیم. با اجرای کد بالا نتیجه زیر را می گیریم:
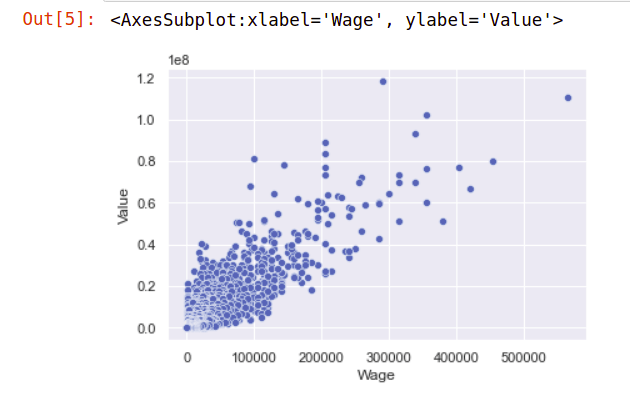
همانطور که می بینید داده های ما به شکل بسیار زیبایی در یک نمودار نقطه ای نمایش داده شده اند و حالا می توانیم داده های خودمان را به شکلی گرافیکی و بسیار زیبا تولید کنیم. حالا سوال دیگری پیش می آید. اگر شما این کد را در سیستم خود اجرا کنید متوجه خواهید شد که نمودار نقطه ای تولید شده رزولوشن کافی را نداشته و کوچک است. دلیل این مسئله، حفظ منابع سیستمی مانند RAM و CPU است تا بی جهت آن ها را درگیر نکنیم. اندازه پیش فرض نمودار برای خواندن آن و دیدن نمایی کلی از داده ها کاملا کافی است اما اگر بخواهیم آن را در یک کنفرانس روی کاغذی بزرگ چاپ کنیم، همه چیز تار خواهد شد. به نظر شما چطور می توانیم این مشکل را حل کنیم؟ اگر یادتان باشد گفتم که متد set در seaborn ظاهر نمودار (مانند تم، اندازه نمودار و غیره) را تنظیم می کند. در این متد، آرگومان خاصی به نام rc وجود دارد که می تواند اندازه نمودار شما را مشخص کند:
import seaborn as sns
sns.set(rc={'figure.figsize':(10, 8)})
graph = sns.scatterplot(x='Wage', y='Value', data=df1)
graph
آرگومان rc یک شیء است که انواع خصوصیات را برای seaborn مشخص می کند. یکی از این خصوصیت figure.figsize می باشد که اندازه نمودار را تنظیم می کند و ما باید مقدارش را به صورت یک tuple پاس بدهیم. شما می توانید با مراجعه به صفحه seaborn.pydata.org/tutorial/aesthetics.html در مورد نحوه زیباسازی ظاهری در seaborn مطالعه کنید. در حال حاضر تنها مشکلی که وجود دارد عدم شناسایی نقطه ها است! یعنی ما یک نمودار زیبا از پراکندگی نقاط مختلف را داریم اما معنی آن برای افراد عادی که Data Frame ما را ندیده اند، اصلا واضح نیست. طبیعتا در حالت عادی مانند یک کنفرانس می توانیم data frame خود را توضیح بدهیم و این کار اصلا مشکلی ندارد اما آیا بهتر نبود که با حرکت موس روی هر کدام از این نقاط، اطلاعاتی به ما نمایش داده شود؟
تعامل پذیر کردن نمودارها به تنهایی نه کار Matplotlib است و نه کار Seaborn، بلکه برای انجام این کار نیاز به کتابخانه کاملا جداگانه ای به نام Bokeh داریم. این کتابخانه یک ابزار بصری سازی (visualization) برای داده های مختلف است اما تفاوت آن در اینجاست که نمودارهای تولید شده تعامل پذیر خواهند بود! برای استفاده از این کتابخانه ابتدا باید آن را وارد کدهایمان کنیم:
from bokeh.plotting import figure,show from bokeh.models import HoverTool
کتابخانه bokeh انواع و اقسام ابزار های مختلف را در خود دارد بنابراین من فقط ابزار هایی را وارد اسکریپت خودم کرده ام که به آن ها نیاز داریم: figure و show و HoverTool. در مرحله بعدی باید یک figure بسازیم. این مرحله دقیقا شبیه به ساخت graph در seaborn است،البته تفاوت هایی جزئی نیز دارد:
from bokeh.plotting import figure,show
from bokeh.models import HoverTool
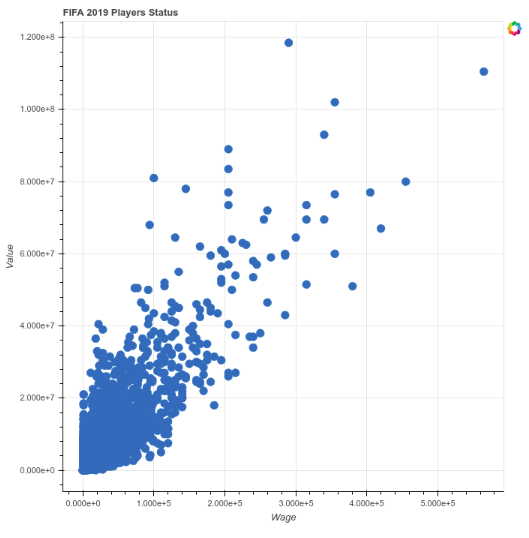
graph = figure(title="FIFA 2019 Players Status", x_axis_label='Wage', y_axis_label='Value', plot_width=700, plot_height=700, tools=[])
graph.circle('Wage', 'Value', size=10, source=df1)
show(graph)
در ابتدا باید title را مشخص کنیم که عنوان نمودار ما است و می توانید هر مقداری را که خواستید به آن بدهید. در مرحله بعدی مقادیر x_axis_label و y_axis_label را داریم که به ترتیب محور x و y را مشخص می کنند. در مرحله بعدی plot_width را داریم که عرض نمودار را تعیین می کند و من آن را روی ۷۰۰ پیکسل گذشته ام. خصوصیت plot_height نیز مسئول تعیین اندازه ارتفاع است. در نهایت آرگومان tools را داریم که فعلا خالی است (در ادامه توضیح می دهم که چه استفاده ای دارد). با انجام این کار تعریف یک graph یا نمودار را داریم. حالا باید آن را به شکلی نمایش بدهیم که مورد نظر ما است. متد های مختلفی در Bokeh برای این کار وجود دارد که line (خط) یا circle (دایره) و غیره را رسم می کنند اما من شخصا circle را ترجیح می دهم بنابراین از این متد استفاده کرده ام. زمانی که از متد circle استفاده می کنید باید محور x و y را به صورت آرگومان اول و دوم مشخص کنید که در کد بالا به ترتیب مقادیر Wage و Value هستند. در مرحله بعدی اندازه دایره ها را تعیین می کنید و نهایتا data frame خود را به آن پاس می دهید. در آخرین مرحله متد show را صدا می زنیم و نمودار تعریف شده را به آن پاس می دهیم. با اجرای این کد یک سربرگ جدید برایتان باز شده و چنین نتیجه ای را می گیرید:
اگر به آدرس مرورگر خود در این سربرگ جدید دقت کنید متوجه خواهید شد که این نمودار تولید شده در قالب یک فایل HTML ساخته شده است بنابراین کیفیت آن عالی است. ما چنین نموداری را با seaborn نیز ساخته بودیم و این چیز جدیدی نیست اما این بار می خواهیم نمودار را تعامل پذیر کنیم بنابراین کد را به شکل زیر ویرایش می کنیم:
from bokeh.plotting import figure,show
from bokeh.models import HoverTool
TOOLTIPS = HoverTool(tooltips=[
("index", "$index"),
("(Wage,Value)", "(@Wage, @Value)"),
("Name", "@Name")
])
graph = figure(title="FIFA 2019 Players Status", x_axis_label='Wage', y_axis_label='Value', plot_width=700, plot_height=700, tools=[TOOLTIPS])
graph.circle('Wage', 'Value', size=10, source=df1)
show(graph)
ما متد HoverTools را صدا زده ایم و آرگومان tooltips را به آن داده ایم. این آرگومان باید یک لیست از tuple های مختلف باشد. مقدار اول هر tuple متنی است که در هنگام hover (حرکت موس روی نقطه) به کاربر نمایش داده می شود و مقدار دوم نیز مقداری است باید در ازای این متن نمایش داده شود. به طور مثال Name به صورت Name نمایش داده می شود اما Name@ مانند یک متغیر است و از داده های جدول استفاده می کند تا نام هر بازیکن را نمایش بدهد. در نهایت باید این متغیر TOOLTIPS را به آرگومان tools در متد ()figure پاس بدهیم. در حال حاضر اگر کد بالا را اجرا کنید همان جدول قبلی را می گیرید با این تفاوت که این بار با حرکت دادن موس روی هر کدام از نقطه ها یک tooltip برایتان باز می شود (یک کادر مستطیل شکل) و اطلاعات مربوطه را نمایش می دهد:
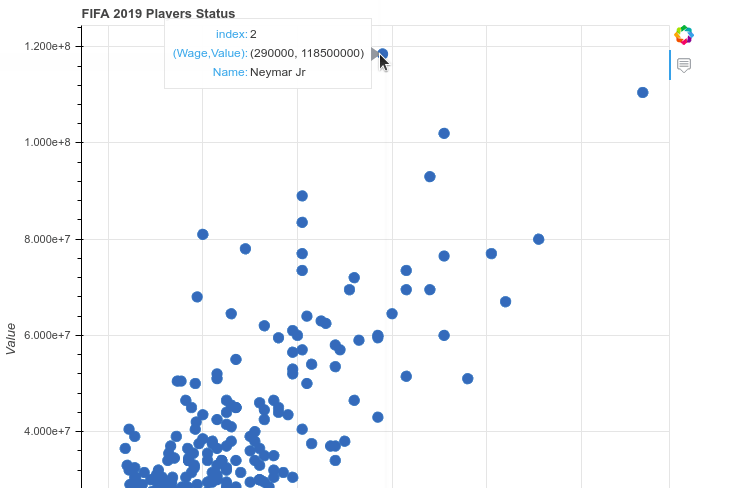
می دانم که کار با چندین کتابخانه در یک جلسه کمی سخت است و ممکن است شما را سر در گم کرده باشد اما این سر در گمی ریشه در احساس نیاز شما برای دانستن تمام این کتابخانه ها می باشد. باید توجه کنید که هدف من از معرفی چندین و چند کتابخانه فقط آشنایی شما با این کتابخانه ها بود تا بدانید گزینه های مختلفی برای انجام یک کار وجود دارد. شما می توانید برای یادگیری جزئی و کامل به صفحه documentation هر کدام از این کتابخانه ها مراجعه کرده و آن را مطالعه کنید.
سخن پایانی
ما در این جلسه در رابطه با انواع و اقسام data visualization یا بصری سازی داده ها صحبت کردیم و تا حدی با Jupyter Notebook ها آشنا شدیم اما اگر یادتان باشد یادگیری ماشینی ۵ (در اصل ۶) مرحله داشت:
- وارد کردن داده درون اسکریپت. ما در این مرحله داده های خودمان را وارد اسکریپت می کردیم که در مثال این جلسه همان فایل csv بود.
- پاک سازی داده ها. در این مرحله باید برای داده های ناقص تصمیم بگیریم که آیا باید آن ها را حذف کنیم یا خیر.
- تقسیم داده ها به داده های تمرینی (training set) و داده های تست (testing set). training set داده هایی است که به عنوان ورودی به سیستم می دهیم تا خوش یاد بگیرد (مثلا ۸۰ ردیف از فایل CSV). زمانی که یادگیری انجام بشود، سیستم یک تابع را به ما برمیگرداند که می توانیم با آن دسته تست یا test set را تست کنیم تا ببینیم آیا تابع تولید شده توسط یادگیری ماشین صحیح است یا خیر.
- ساخت مدل. در این روش باید از الگوریتم یادگیری خاصی استفاده کنیم تا بتوانیم یادگیری ماشینی را داشته باشیم. این الگوریتم معمولا توسط دیگر افراد از قبل نوشته شده است و خودمان هیچگاه الگوریتم نویسی نمی کنیم.
- بررسی خروجی. در این مرحله نتایج برگردانده شده از سیستم خودمان را بررسی می کنیم تا ببینیم آیا نتیجه قابل قبولی داریم یا خیر.
- ارتقاء و بهبود سیستم. در این مرحله کد ها را ویرایش می کنیم تا نتایج بهتری به دست بیاوریم.
ما تا این مرحله در مورد دو مرحله اول صحبت کرده ایم اما هنوز به مرحله سوم (ساخت مدل) و مرحله چهارم (بررسی خروجی) نرسیده ایم بنابراین نمی توان گفت که واقعا با یادگیری ماشینی کار کرده ایم. در جلسه آینده وارد مبحث شناسایی تصاویر شده و به صورت واقعی و کامل با یادگیری ماشینی کار می کنیم. مباحث بررسی شده در این جلسه به عنوان پیش زمینه ای برای کار با Jupyter Notebook ها و آماده سازی داده هایمان بود. طبیعتا انجام این پروژه بزرگ کمی سنگین خواهد بود و چندین جلسه طول خواهد کشید اما مثال بسیار خوبی از یادگیری ماشینی را به ما نشان می دهد.

دورههای آموزشی مرتبط

مقالات مرتبط

14 شهریور 1402

23 مرداد 1402

21 مرداد 1402


آخرین سوالات کاربران
Alorazaeri در 6 سال قبل پرسیده:
Alorazaeri در 6 سال قبل پرسیده:
ما را دنبال کنید



در این قسمت، به پرسشهای تخصصی شما دربارهی محتوای مقاله پاسخ داده نمیشود. سوالات خود را اینجا بپرسید.